复合函数的偏导数公式
智能座舱这一概念在当下已经传播开来,那么,你是否了解智能座舱背后隐藏的技术或算法基础?这篇文章里,作者围绕深度学习算法及卷积神经网络、损失函数等内容做了分析解读,不妨来看一下。

智能座舱,实在传统的车载座舱系统的基础上增加了智能化的属性,通过感知(语音、视觉)、认知、决策、服务的过程使车辆能够主动地服务于驾驶员和乘客,从而提升座舱的用户体验,带来更好的安全、便捷、趣味性体验。
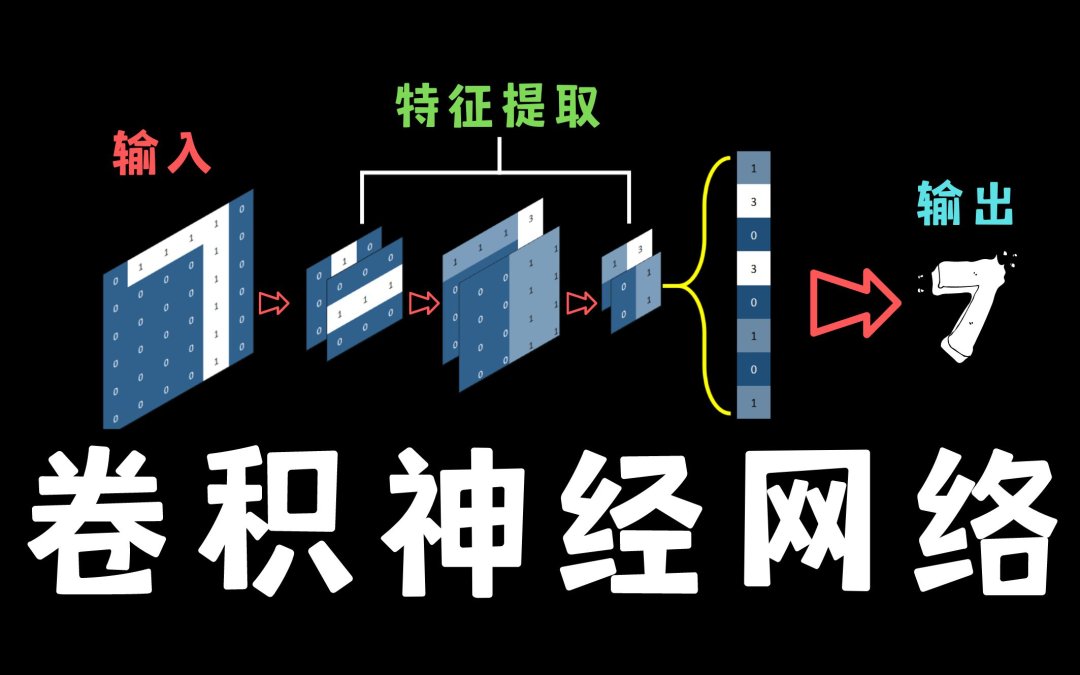
随着2016年谷歌的AlphaGo以4:1战胜韩国的围棋高手李世石,深度学习这一未来人工智能领域最重要,最核心的科技立即成为人们关注的焦点。
一、传统机器学习与深度学习
两者都需要对数据进行预处理,传统的机器学习算法通过人工设计特征提取器,在复杂任务下,人工设计的特征提取器效果不佳,讲提取的特征传输到训练好的分类器中进行预测;深度学习的算法则是在数据预处理后,根据任务的复杂性设计模型,然后对模型进行训练。
虽然深度学习算法在复杂任务重仍然拥有较好的效果,但该类算法也拥有模型可解释性差等缺点,比如说无法解释模型中的各个模块分别提取什么样的具体特征。
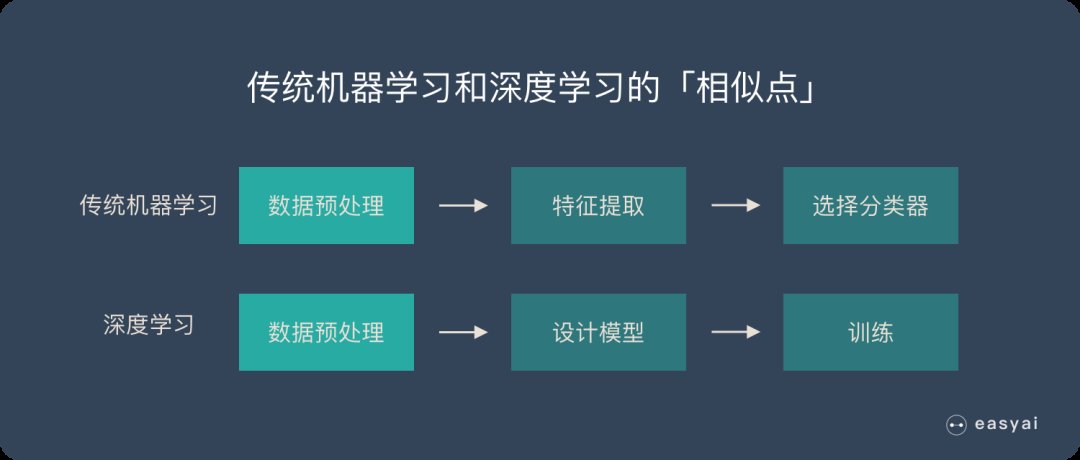
传统机器学习与深度学习的流程对比
随着算法突破,深度神经网络作为深度学习的一类实例化结构逐渐被广泛应用。其中在视觉感知场景,针对图像数量较大的特点,通常采用卷积神经网络(CNN)这一结构对图像数据进行处理。
深度学习算法通常由三部分组成,包括神经网络模型、损失函数和优化方式。深度神经网络模型实际上可以理解成就是一个复杂的函数,这个函数将输入映射到输出值,该函数是有许多个简单函数复合而成。
卷积神经网络就是一个拥有大量可训练参数的复杂函数,其中参数可训练意味着通过参数的更改,模型的预测能力越来越强,预测值与真实值之间的差异越来越小。而衡量模型输出值与预测值之间差距的方式就是通过设计的损失函数实现。优化方式的选择意味着模型通过怎样的方式进行参数优化,从而实现损失函数的最小化,一般的优化方式为反向传播算法加上梯度下降。
二、卷积神经网络
卷积神经网络在计算机视觉中应用广泛,常见的图像分类识别、目标检测追踪、图像分割等。自从2012年,AlexNet在ImageNet数据集上取得不错的效果后,大量的CNN模型被提出,广泛被使用的CNN模型有VGG、ResNet、DenseNet、MobileNet、ResNeXt等。
根据“端到端”的设计思路,网络结构大致分为输入层、隐藏层和输出层,其中隐藏层主要完成对输入数据进行特征提取和对提取到的特征进行信息整合,用于预测。结构中用于特征提取的层包括卷积层、池化层、激活函数等,用于分类识别的包括全连接层等。
其中,用于特征提取的模块,一般被称为backbone,其基本结构与模块如下图所示:

神经网络基本结构与模块
输入图像传入网络后,通常由卷积层对输入进行卷积,实现特征提取;批量归一化层对卷积后的操作进行处理,统一数据分布;激活层通过激活函数实现数据的非线性转换,增加网络表达能力,从功能上模拟生物神经元的激活和抑制状态;池化层降低特征图尺寸,使得图像特征凸显。由多个基本模块搭建而成的backbone对输入图像进行特征提取,在提取过程中,数据以定数量的特征图进行传输。
三、损失函数
在网络训练过程中,需要通过损失函数来评估模型对输入数据的最终预测和真实标签之间的误差,深度学习中的损失函数需要根据当前的应用场景进行相应设计,但不管是哪张损失函数,都可以总结出以下特点:
- 恒非负。损失函数计算的是模型预测值与真实值之间的差距,模型根据损失函数进行优化后,最好的情况是损失函数的值为0,即模型的预测输出完美拟合真实值,只要有一点拟合的偏差那就会让损失增加。
- 模型预测值与真实值之间误差越小,函数值越小。
- 损失函数收敛快。收敛快的意思就是指在迭代优化这个损失函数的过程中,需要让它比较快地逼近函数极小值,逼近函数值低点。
四、模型训练及测试
卷积神经网络的训练过程即为模型通过对训练数据的迭代学习,不断对网络中可训练参数进行优化直到损失函数最小化的过程。训练即是模型的多次迭代,每次迭代涉及两个过程,即前向传播和反向传播。而模型测试即是在模型没有学习过的测试数据集上进行前向传播。前向传播中,数据根据网络中的计算图从输入层到输出层进行计算。
具体来说,当图像输入后,经过网络中的卷积层和池化层的运算,抽象出图像中的高级特征,然后将特征图展平后传输到全连接层等方向,完成模型的预测。反向传播中,根据链式法则,推理误差对于网络中所有可训练参数的偏导数依次从输出层向输入层被求解,存储下来的梯度被用来优化参数。
与许多其他机器学习模型相同,卷积神经网络同样是通过梯度下降来优化模型的参数。根据凸优化理论可知,由于神经网络模型复杂度较高,同时其损失函数一般为非凸(non-convex)函数,最小化损失函数时存在着局部最优解,使得非凸优化实现全局最优的难度增加。因此,在深度神经网络模型的反向传播中,一般采用小批量随机梯度下降。
五、模型压缩
卷积神经网络中的模块根据是否含有可训练参数可以大致分为两类:一类是含有权重和阈值的卷积层、全连接层等,且权重和阈值的数量在具体任务下有优化的空间;另一类是非线性激活层、池化层等,这类模块不含有任何可训练参数。
在一定程度上,模型参数量决定着模型对设备的存储消耗,该模型的计算量决定着模型运行时的实时性。模型压缩和加速则是针对具体任务,在保持模型性能的同时,降低模型的复杂度和计算量的一种方法。
本文由 @ALICS 原创发布于人人都是产品经理。未经许可,禁止转载
题图来自Unsplash,基于CC0协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。
","gnid":"942eed98462875009","img_data":[{"flag":2,"img":[{"desc":"","height":"420","title":"","url":"https://p0.ssl.img.360kuai.com/t0133c3ac222211e8e4.jpg","width":"900"},{"desc":"","height":"675","title":"","url":"https://p0.ssl.img.360kuai.com/t015db34d758c2de158.jpg","width":"1080"},{"desc":"","height":"460","title":"","url":"https://p0.ssl.img.360kuai.com/t01a3bb5780eaea1d1e.jpg","width":"1080"},{"desc":"","height":"407","title":"","url":"https://p0.ssl.img.360kuai.com/t014837e1af850764b4.jpg","width":"500"}]}],"original":0,"pat":"art_src_3,fts0,sts0","powerby":"pika","pub_time":1706839320000,"pure":"","rawurl":"http://zm.news.so.com/aa7e7da0b0b85b29c2564d453a3653cc","redirect":0,"rptid":"82bfa530518ad88c","rss_ext":[],"s":"t","src":"人人都是产品经理","tag":[{"clk":"ktechnology_1:机器学习","k":"机器学习","u":""}],"title":"智能座舱算法基础之深度学习篇
苍哈信3842多元复合函数隐函数求偏导 -
鲁琼柱15320699282 ______ 两边对y求偏导 z·F'1+y(∂z/∂y)F'1+F'2+x·(∂z/∂y)F'2=0 (∂z/∂y)(F'1+x·F'2)=-z·F'1-F'2 ∂z/∂y=-(z·F'1+F'2)/(F'1+x·F'2)
苍哈信3842设函数u=f(x,y,z),y=g(x,t),t=v(x,z)均有一阶连续偏导数,则偏u/偏x=? -
鲁琼柱15320699282 ______ 由复合函数偏导数一步步来:偏u/偏x=偏f/偏x+(偏f/偏y)(偏y/偏x)=偏f/偏x+(偏f/偏y)(偏g/偏x+(偏g/偏t)(偏t/偏x)),最后的偏t/偏x就是偏v/偏x.你再写成符号形式,注意括号
苍哈信3842高等数学中关于求偏导数的问题? -
鲁琼柱15320699282 ______ 第一步 ∂²z/∂x²=∂(∂z/∂x)/∂x z对x的二阶偏导数是“z对x的一阶偏导数”这个函数的一阶偏导数 第二步 对复合函数∂z/∂x=yz/(e^z-xy)求一阶偏导数 利用f(x)/g(x)的导数这个公式,但是注意因为∂z/∂x里面含有z,而z又是关于x的函数,所以对z求偏导数得到的是∂z/∂x,(再具体一点说就是yz/(e^z-xy)中的z要看成z(x,y)这样一个函数) 第三步 将∂z/∂x=yz/(e^z-xy),代入到上一步的结果当中 第四步 整理式子
苍哈信3842复合函数的导数//怎么求? -
鲁琼柱15320699282 ______ 复合函数的求导公式
苍哈信3842f1和f2是怎么来的?多元复合函数求导法则 -
鲁琼柱15320699282 ______ 一般是复合函数,在链式法则求导时会这么写f1,f2指的是指的是函数f 里自变量的位置按顺序排即可比如z=f(u,v),u即u(x,y),v即v(x,y)那么对x求偏导数时,1指的就是u,2则是v就首先z'x=f1' *∂u/∂x+f2'*∂v/∂x 即可
苍哈信3842如图,高数,多元函数的偏导数,划红圈部分,f(u)是怎么来的? -
鲁琼柱15320699282 ______ 就是除法的导数法则,第一个对x求偏导,把x当成自变量,第二个对y求偏导,把y当成自变量.根据除法导数法则,下面平方,上面是上导下不导减下导上不导.这里面u=x2-y2,所以还有复合函数的导数.
苍哈信3842求复合函数的偏导数 设Z=u^2 lnv , u=y/x, v=x^2+y^2, 求 az/ax ,az/ay -
鲁琼柱15320699282 ______ az/ax=az/au+au/ax=2ulnv-y/x^2 az/ay=az/av+av/ay=u^2/v+2y 然后再稍微化简一下就行啦!
苍哈信3842复合函数的导数怎么求? -
鲁琼柱15320699282 ______ 总的公式f'[g(x)]=f'(g)*g'(x) 比如说:求ln(x+2)的导函数 [ln(x+2)]'=[1/(x+2)] 【注:此时将(x+2)看成一个整体的未知数x'】 *1【注:1即为(x+2)的导数】 主要方法:先对该函数进行分解,分解成简单函数,然后对各个简单函数求导,最后将求导后的结果相乘,并将中间变量还原为对应的自变量.
苍哈信3842z=e^(uv) u=ln[根号(x^2+y^2)] v=arctan(y/x)复合函数的偏导数或导数 -
鲁琼柱15320699282 ______[答案] u=ln[根号(x^2+y^2)]=1/2ln(x^2+y^2)z'x=ve^(uv)*1/[2(x^2+y^2)]*2x+ue^(uv)*1/(1+y^2/x^2)*(-y/x^2)=ve^(uv)*x/(x^2+y^2)-ue^(uv)*y/(x^2+y^2) (u,v自己代入)z'y=ve^(uv)*1/[2(x^2+y^2)]*2y+ue^(uv)*1/(1+y^2/x...
苍哈信3842复合函数的偏导数问题.设z=y^lnx,则(δ^2)z/δ(x^2)=多少.麻烦高手把过程都具体写下, -
鲁琼柱15320699282 ______[答案] =(58+42)*(58-42)+(60-2)*(60+2) =100*16+60平方-2平方 =1600+3600-4 =5196 平均速度是△s-△t =[(3+△t)^2+3-(t^2+3)]/△t =(6△t+△^2)/△t =6+△t 选A