扫描版pdf怎么搜索文字
作者:效率-软件库
众所周知,七八十年代甚至更早的论文文件形式通常是扫描版或图片版PDF文档,这样的PDF文档无法复制和检索文字,想要摘录文字和做笔记就非常不方便,只能通过OCR来识别转为文字版PDF文档。那么,市面上都有哪些OCR识别软件?哪款最好用呢?
今天,为您介绍几款市面上较为知名的OCR识别PDF软件,并为您推荐一款最佳选择!
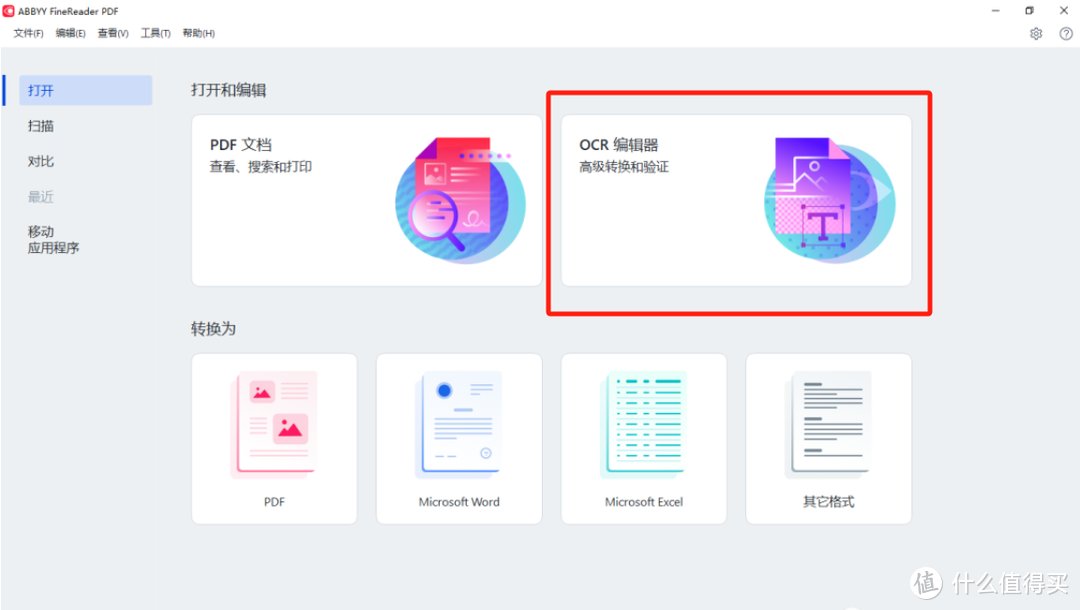
OCR识别软件一:ABBYY Fine Reader
ABBYY Fine Reader是一款专业的OCR软件,它可以识别多种语言和文件格式,支持批量处理和自动化任务,可以将扫描的文档转换为可编辑的文本文件。它不仅可以识别文本,还可以识别表格、图像和布局,使得文档的转换更加准确和方便。同时,ABBYY Fine Reader 还可以标记 PDF、无差异对比不同文件。它适配 Win 和 Mac,只不过很多内容需要付费才能使用。
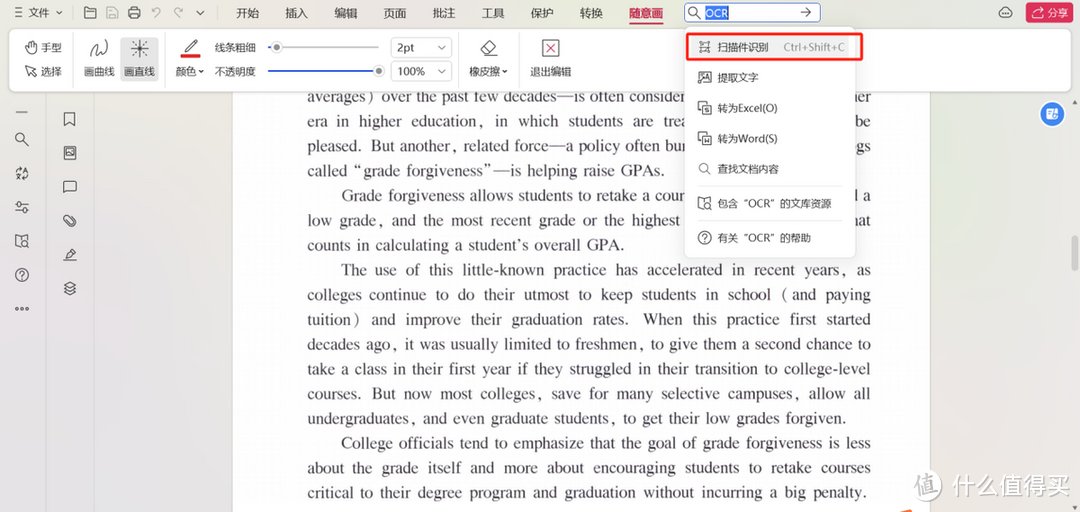
OCR识别软件二:Microsoft Office
Microsoft Office是一款办公软件套件,其中包括了Word、Excel等常用软件,它也提供了OCR识别功能,用户可以将纸质文档或图片中的文字识别为Word文档,方便进行编辑。我们只需要在APP中找到添加框,选择菜单栏中的搜索框,点击“扫描件识别”功能,接着选取所需识别扫描的文本,最后系统即可自动生成相对应的文本内容。
OCR识别软件三:UPDF
UPDF是一款智能PDF阅读和编辑软件,它支持多种功能,其中主要包括OCR识别功能。绿色免安装,支持离线功能,支持批量识别,支持截图和本地图片识别,还可以识别更多语言。
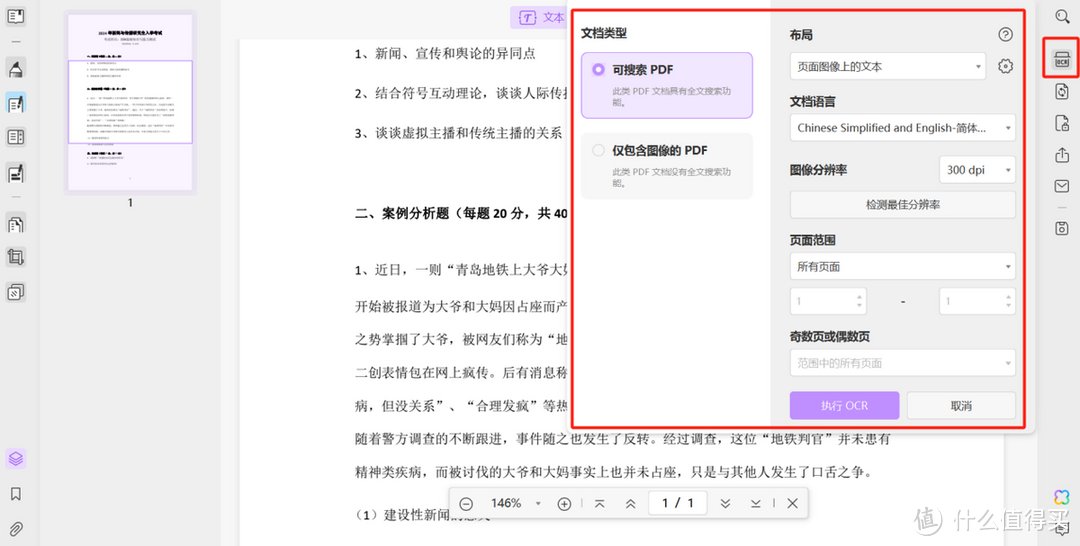
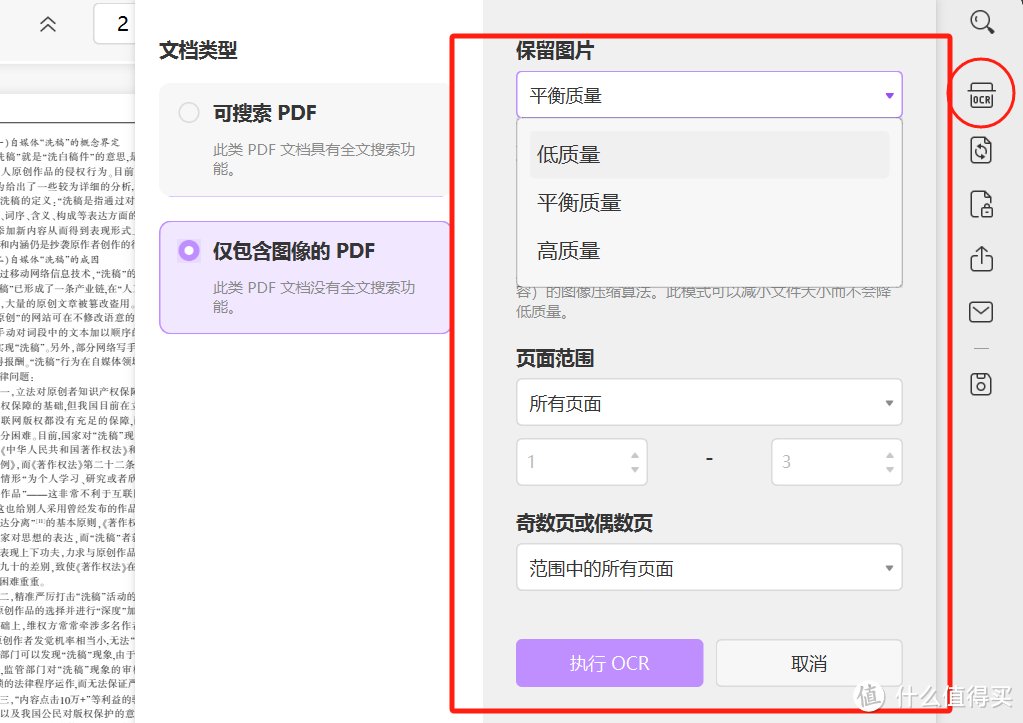
UPDF提供了OCR三种布局模式。主要包括:仅文本和图片、页面图像上的文本、页面图像下的文本。个性化满足转化需求。
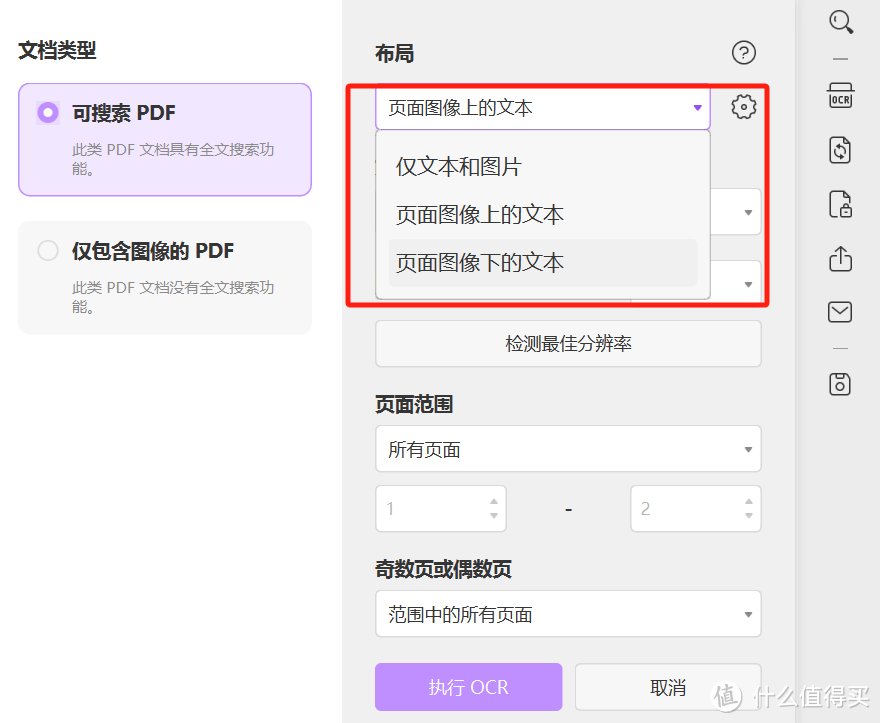
只需点击右侧的OCR,确定页面上语言以及页面范围 ,点击执行OCR即可一键转换成可编辑的文字,简单也操作,效果更佳,速度更快。
软件适用多种场合,比如论文文本识别、图片识别、社交群批量文件、以及不可复制场景文字文本内容提取等等。
UPDF可以从文本、图片中识别出汉字,英文,数字,准确率高达 99%,目前软件已经开源,支持Windows和Mac电脑以及iPhone, iPad和Android 智能手机上无缝使用。
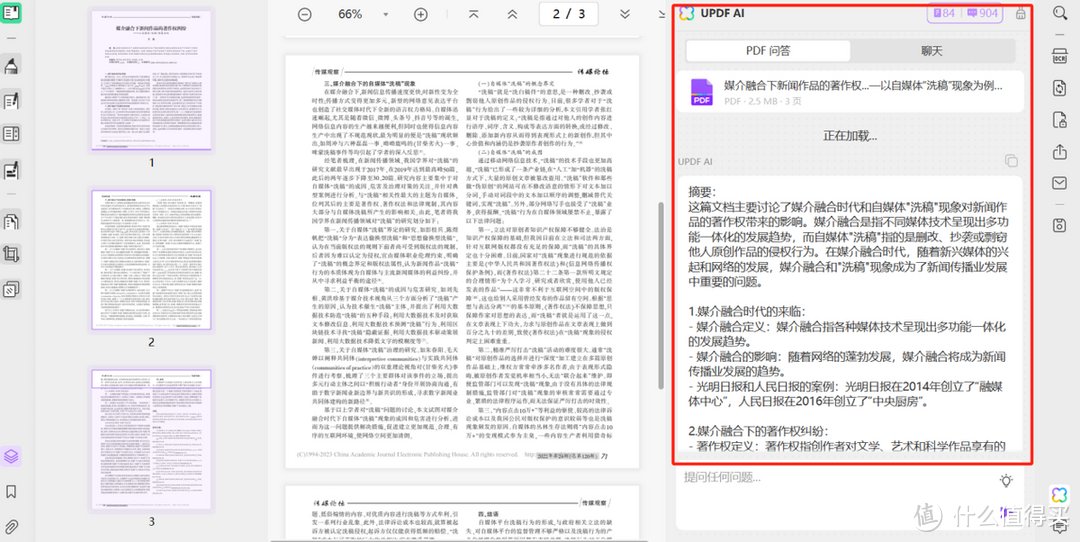
当然,UPDF除了OCR识别以外,其AI功能也很强大。例如,可以通过UPDF AI进行文本翻译、文本解析、片段润色、编撰重写等功能,让AI帮辅阅读PDF,极大的节省时间。
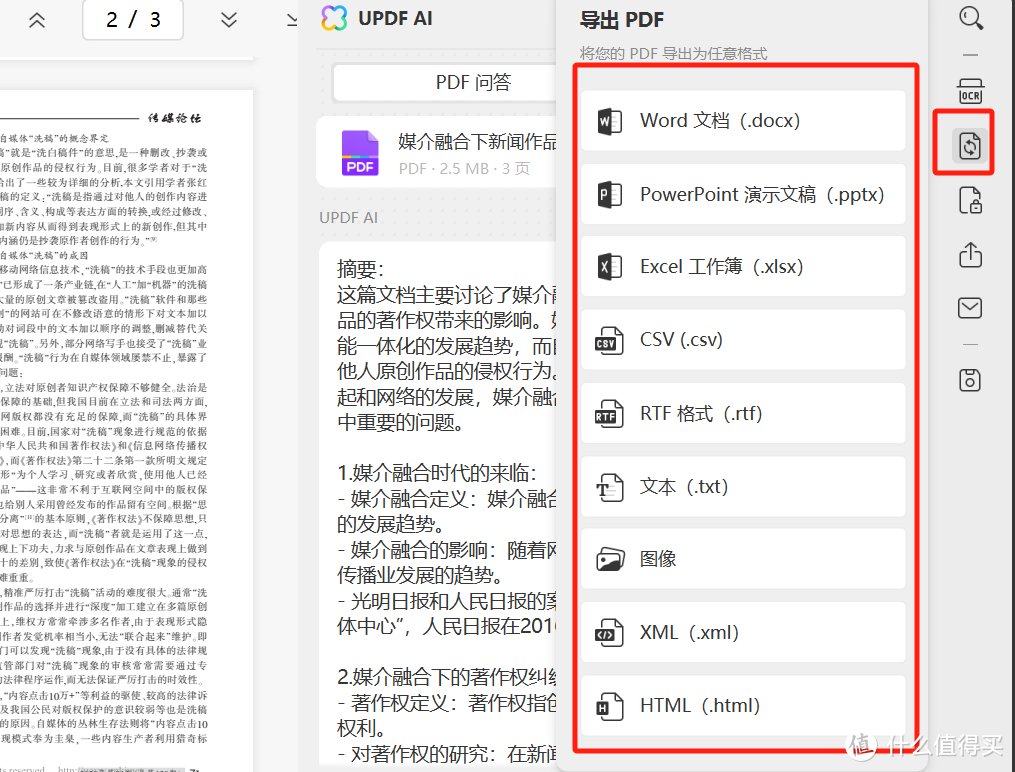
除了对PDF进行OCR扫描、阅读、注释、编辑等操作外,你还经常需要进行文档格式的转换,UPDF编辑器有丰富的转换功能,包括Word 、PPT、Excel等 ,你可以在UPDF编辑器中轻松处理。
总结
以上3款OCR识别软件,个人最推荐UPDF,不仅具备高识别准确度和简单易用的特点,还提供PDF编辑、转换、AI助手等功能,能满足大多数人需求,值得一试。
下载地址:【官网】UPDF-新一代AI智能PDF编辑器
阅读更多办公软件精彩内容,可前往什么值得买查看
","gnid":"951863bfa98cc3347","img_data":[{"flag":2,"img":[{"desc":"","height":"610","title":"","url":"https://p0.ssl.img.360kuai.com/t017bbed569628c1189.jpg","width":"1080"},{"desc":"","height":"512","title":"","url":"https://p0.ssl.img.360kuai.com/t01220b771bca4a3d02.jpg","width":"1080"},{"desc":"","height":"546","title":"","url":"https://p0.ssl.img.360kuai.com/t01186e7912614ab29b.jpg","width":"1080"},{"desc":"","height":"723","title":"","url":"https://p0.ssl.img.360kuai.com/t01938f1e524e48f8d6.jpg","width":"880"},{"desc":"","height":"475","title":"","url":"https://p0.ssl.img.360kuai.com/t018f6fb18d3b44d079.jpg","width":"948"},{"desc":"","height":"552","title":"","url":"https://p0.ssl.img.360kuai.com/t0155693529d04c974e.jpg","width":"1080"},{"desc":"","height":"723","title":"","url":"https://p0.ssl.img.360kuai.com/t01aa484645f7048abc.jpg","width":"1023"},{"desc":"","height":"542","title":"","url":"https://p0.ssl.img.360kuai.com/t010c2a09d80a0708bd.jpg","width":"1080"},{"desc":"","height":772,"title":"","url":"https://p0.ssl.img.360kuai.com/t01c8d2aafa52b1e589.jpg","width":1015}]}],"original":0,"pat":"art_src_1,fts0,sts0","powerby":"pika","pub_time":1702368596000,"pure":"","rawurl":"http://zm.news.so.com/ce5fbf5f071e2f0dcd89bf42752601b4","redirect":0,"rptid":"983f1d6997aa1040","rss_ext":[],"s":"t","src":"什么值得买","tag":[{"clk":"ktechnology_1:word","k":"word","u":""},{"clk":"ktechnology_1:excel","k":"excel","u":""},{"clk":"ktechnology_1:mac","k":"mac","u":""},{"clk":"ktechnology_1:pdf","k":"pdf","u":""}],"title":"3大OCR识别软件!个个都是好用神器!
郎皆毛4444pdf中不能输入汉字搜索,如何处理 -
席牧柳15662501921 ______ pdf文件有两种,一种是文字形式的可以编辑搜索等,另外一种是扫描的图片类型的,文件内容都是图片当然不能搜索.
郎皆毛4444急!!!用什么方法可以识别PDF格式中(扫描的图片)的文字并复制 -
席牧柳15662501921 ______ 用ScanSoft PDF Converte,安装完成后不须任何设置,它会自动整合到Word中.当我们在Word中点击“打开”菜单时,在“打开”对话框的“文件类型”下拉菜单中可以看到“PDF”选项,这就意味着我们可以用Word直接打开PDF文档了!...
郎皆毛4444怎么用vc++实现对pdf文档关键字的搜索 -
席牧柳15662501921 ______ 朋友,你想输入关键字,就能找到PDF文件,最简单的方法是用关键字命名,然后ctrl+f搜索.还有我告诉你,PDF文献资料都是纯图片的,怎么可能实现用关键字索引呢?看来你是不懂PDF这种格式啊我是一楼你的PDF文献资料是文献扫描制作的吗?(大部分的PDF文献资料都是扫描得到的),你试试任意打开一个你公司的PDF文献资料,如果你能将文字选中,说明不是扫描得到的,如果不能选中则是扫描得到的.如果是扫描制作的PDF文件,不能搜索文章里面的字如果不是扫描制作的PDF文件,你就用AdobeReader的搜索功能,搜索范围:你保存PDF的那个文件夹.(如图)实现建立局域网共享,这个我不了解的.我能帮你的就这么多了.
郎皆毛4444怎么知道PDF是扫描版 -
席牧柳15662501921 ______ 判断pdf是否是扫描版,大概可从以下几个方面入手:(以下所说扫描版,与某些由图像文件转换而来的pdf,在判断性质上近似,所以就包括了图像版.)不一定正确,请大家修正. 1.经验法:一般正规出版社出版的书籍pdf,大多是扫描版的...
郎皆毛4444如何提取PDF文件中的文字? -
席牧柳15662501921 ______ 下个Adobe PDF,直接可以复制
郎皆毛4444怎么给图片制作的pdf电子书增加查找功能(即OCR处理)?谢谢 -
席牧柳15662501921 ______ 你说的是双层PDF,一层文字,一层图片 所以才可以进行查找
郎皆毛4444在PDF里面图片中的文字为什么用CTRL+F查找不到? -
席牧柳15662501921 ______ 有可能客户图片里的文字不属于图片这一层的,因为本身图片里的文字确实是CONTROL+F找不到的!
郎皆毛4444怎样将PDF格式中的内容进行文字识别? -
席牧柳15662501921 ______ 晕,现在有好多这样的工具的,你直接在网页里搜索,PDF转DOC,就会出来好多了,DOC的你再把他复制到TXT里不就是纯文本了吗
郎皆毛4444扫描PDF文件的文字怎么提取出来? -
席牧柳15662501921 ______ 请你试用汉王PDF OCR8.1简体中文版的PDF识别软件转换,简单易用免费,无限制,但要逐页转换.方法是下载安装汉王pdf ocr8.1,运行并打开PDF文件,如PDF的字号较小,在打开时请不用默认分辨率,自行设定最高分辨率为600DPI,逐页打开PDF文件后,可直接进行识别,但最好是进行水平调整,手工设置识别区域,分出文字区、表格区和图片区,然后才开始识别,这样的识别率较高,识别后进行校稿,对照原稿校正错别字.最后是选择已识别转换校对好的页面,在菜单-输出-到指定输出文件格式,可输出为TXT、RTF、XLS等文件格式.如要输出WORD格式,请选择RTF格式,用WORD打开后,将文字从文字框中复制出来按需要编辑一下即可.
郎皆毛4444急~~用什么软件提取图像或者PDF文件里面的文字??我最近扫描了
席牧柳15662501921 ______ 用acrobat reader和尚书六号都可以阿,我就用这两种软件的 下面是下载地址