3080ti参数详细
Alex 发自 凹非寺
量子位 | 公众号 QbitAI
春暖花开,各位深度学习er想不想给自己的“丹炉”升级一波?
“炼丹”爱好者们应该知道,在该领域中,**GPU的总体表现完胜CPU。
那么GPU应该怎么选?不妨来看看这篇超级详尽的“2023版GPU选购指南”。
知名测评博主、华盛顿大学在读博士Tim Dettmers亲测后,写下万字长文,手把手教你Pick性价比最高的显卡,避免踩雷。

△光是目录就有这么长……
至于谁是性价比之王,不卖关子,这里先放上Tim哥的结论:
对于16位训练过程,RTX 3080的性价比最高;对于8位和16位推理,RTX 4070Ti的性价比最高。
有意思的是,不只这俩,他在本文推荐的显卡全是英伟达家的——Tim哥觉得,对于深度学习,“AMD GPU+ROCm”目前还打不过“NVIDIA GPU+CUDA”。

手把手教你挑GPU
Tim哥自制了一张表格,展示出在训练和推理过程中,一美元能买到多少算力;这在一定程度上体现了英伟达众显卡的性价比。
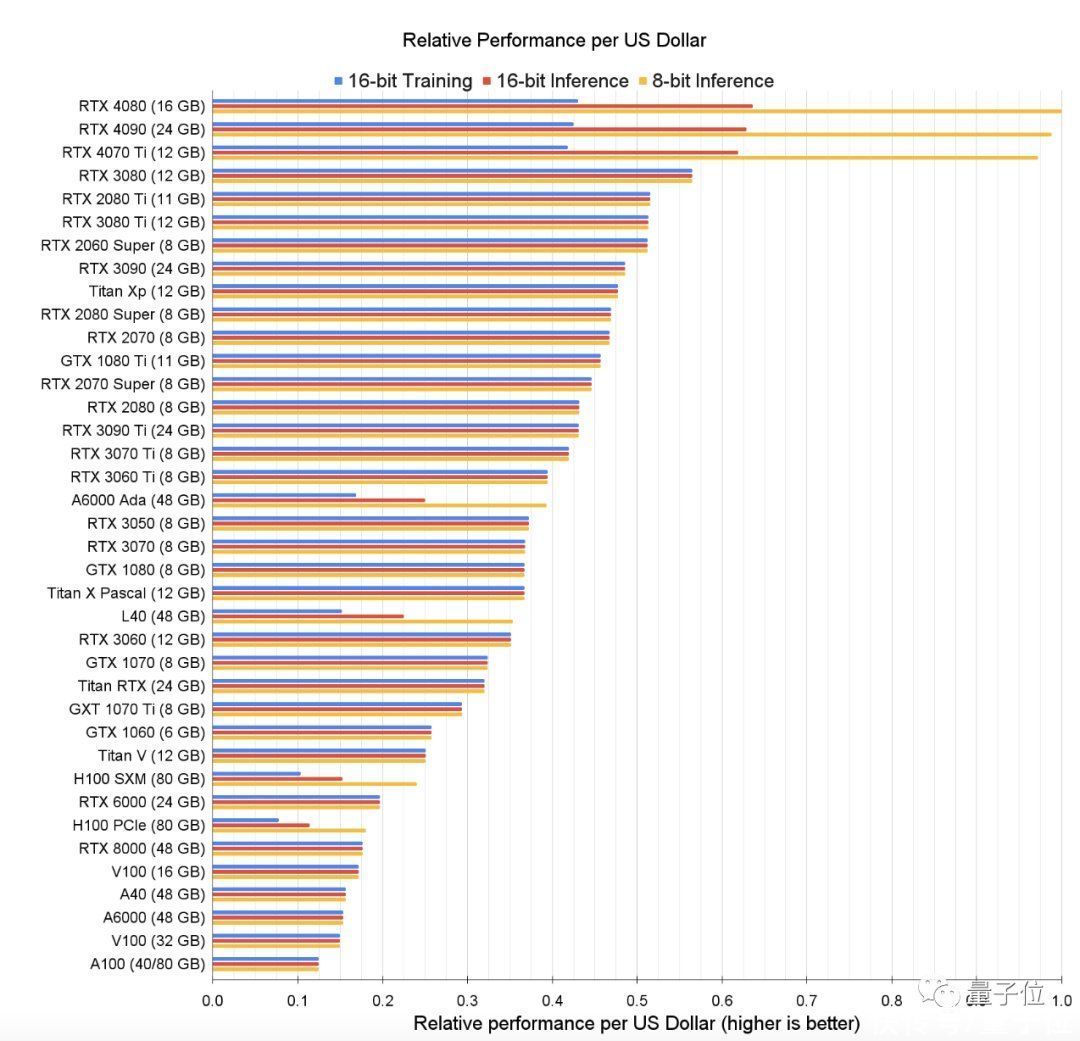
△蓝色-16位训练;红色-16位推理;黄色-8位推理
看到这个,你可能一脸问号:从表格来看,不是RTX 4080在8位和16位推理上的性价比更高吗?
其实,咱们开头说的是“综合性价比”——
除了看一美元能买多少算力,还要结合显卡的运行成本,比如电费。所以总的来说,还是RTX 4070Ti的性价比更高。
虽然RTX3080和RTX 4070 Ti性价比高,但这俩的内存是个明显短板:
Tim哥指出,12GB在很多情况下都不够用,要运行Transformer模型的话,至少需要24GB。
于是,Tim哥又贴心地做了一个小程序,帮你根据不同的任务选择最合适的GPU。

其背后的核心思想是:不管干啥,一定要保证GPU的内存满足你的需求。
首先,要弄清楚这个GPU是个人用还是公用,还有就是要处理什么任务——比如,是要训练语言大模型(LLM)吗、参数量有没有超过130亿?还是就做点小项目?
然后再根据自己的钱包情况,参考上面的表格,选择最合适的GPU。
举个例子:
如果要训练LLM且参数量超过130亿,不差钱的可以选择支持Azure公有云的A100或者H100;追求性价比的话,可以选支持AWS的A100或者H100。
但如果预算实在有限,建议放弃……
(在亚马逊上,40GB的英伟达Tesla A100售价为11769美元起,约合人民币79529元。当然这都是针对国外的情况,在国内炼丹仅供参考)
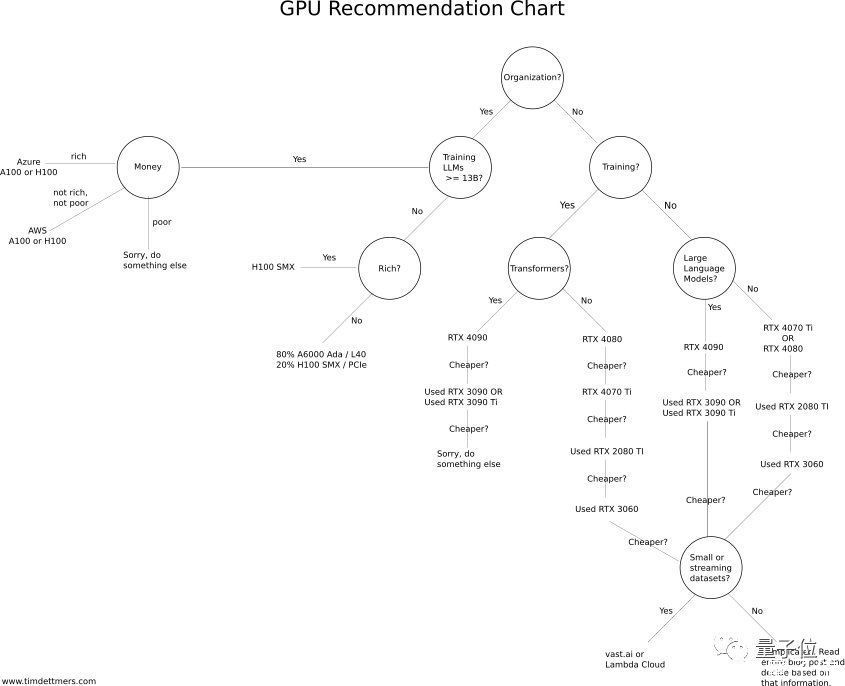
另外,Tim哥还支了一招:最好用云GPU(比如Lambda云)来估测一下所需的GPU内存(至少12GB用于图像生成,至少24GB用于处理Transformer)。
其实假如GPU仅偶尔使用(每隔几天用几小时),甚至都不用去买个实体的,用云GPU就可以了。
对了~如果你真的不在乎这点(?)钱,就要追求极致性能,那可以看看这张表,即GPU的原始性能排行。
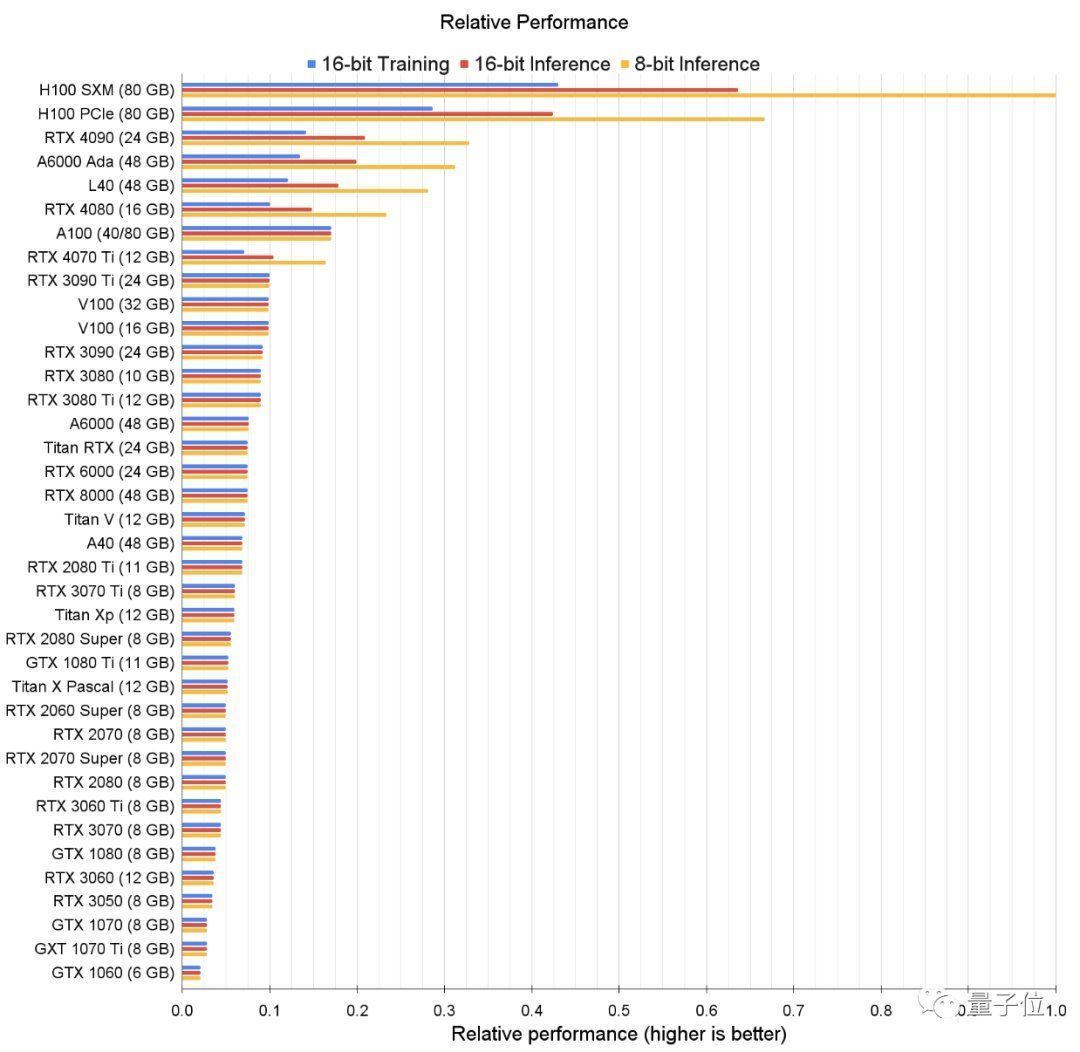
那如果实在钱不够,即使是Tim哥推荐的最便宜的GPU也买不起,还有办法吗?
那可以考虑二手呀!
先去买个便宜的GPU用于原型设计和测试,然后在云端进行全面的实验和测试。
关键性能点有哪些?
盘点完英伟达的一堆GPU后,再来叙一叙关乎深度学习速度的几大GPU性能关键点。
(如果你想稍微深入了解一些,请接着往下看。)
Tim哥指出,重点有四:GPU的内存、核心、Tensor Core和缓存。
而其中最重要的是Tensor Core。
Tensor Core是英伟达为其高端GPU开发的一项技术,本质上,就是加速矩阵乘法的处理单元。其中Tensor即张量,是一种能表示所有类型数据的数据类型。
Tim表示,在所有深度神经网络中,最昂贵的部分是矩阵乘法,而有了Tensor Core,运算速度会变得非常快,有助于大大减少成本。
就拿一个入门级的32×32矩阵乘法来说,通过Tensor Core,将矩阵乘法的运算时间从504个周期,降低到235个周期,直接减半。
而且即便是超大规模的矩阵运算,Tensor Core也能轻松处理。在规模堪比GPT-3的训练中,Tensor Core的TFLOPS利用率也就约为45-65%。
而当两个GPU都有Tensor Cores时,要比较它们性能,最佳指标之一就是内存带宽。
例如,A100 GPU的内存带宽为1555GB/s,而V100为900GB/s。因此,A100和V100相比,运算速度大概是后者的1555/900=1.73倍。
由此可见,内存带宽会影响到Tensor Core的性能发挥。于是研究人员开始寻找其他GPU属性,使内存数据传输到Tensor Core的速度更快。
然后,他们发现,GPU的一级缓存、二级缓存、共享内存和使用的寄存器数量也都是相关因素。
对于缓存来说,数据块越小,计算速度越快;所以需要把大的矩阵乘法,划分成小的子矩阵乘法。研究者们把这些小的子矩阵乘法称为“内存碎片”*(memory tiles)。
一部分“碎片”被加载到Tensor Core中,由寄存器直接寻址。
根据英伟达Ampere架构的规则,举个例子~
把每一个权重矩阵都切成4个“碎片”,并假设其中两个为零——于是就得到了一堆稀疏权重矩阵。
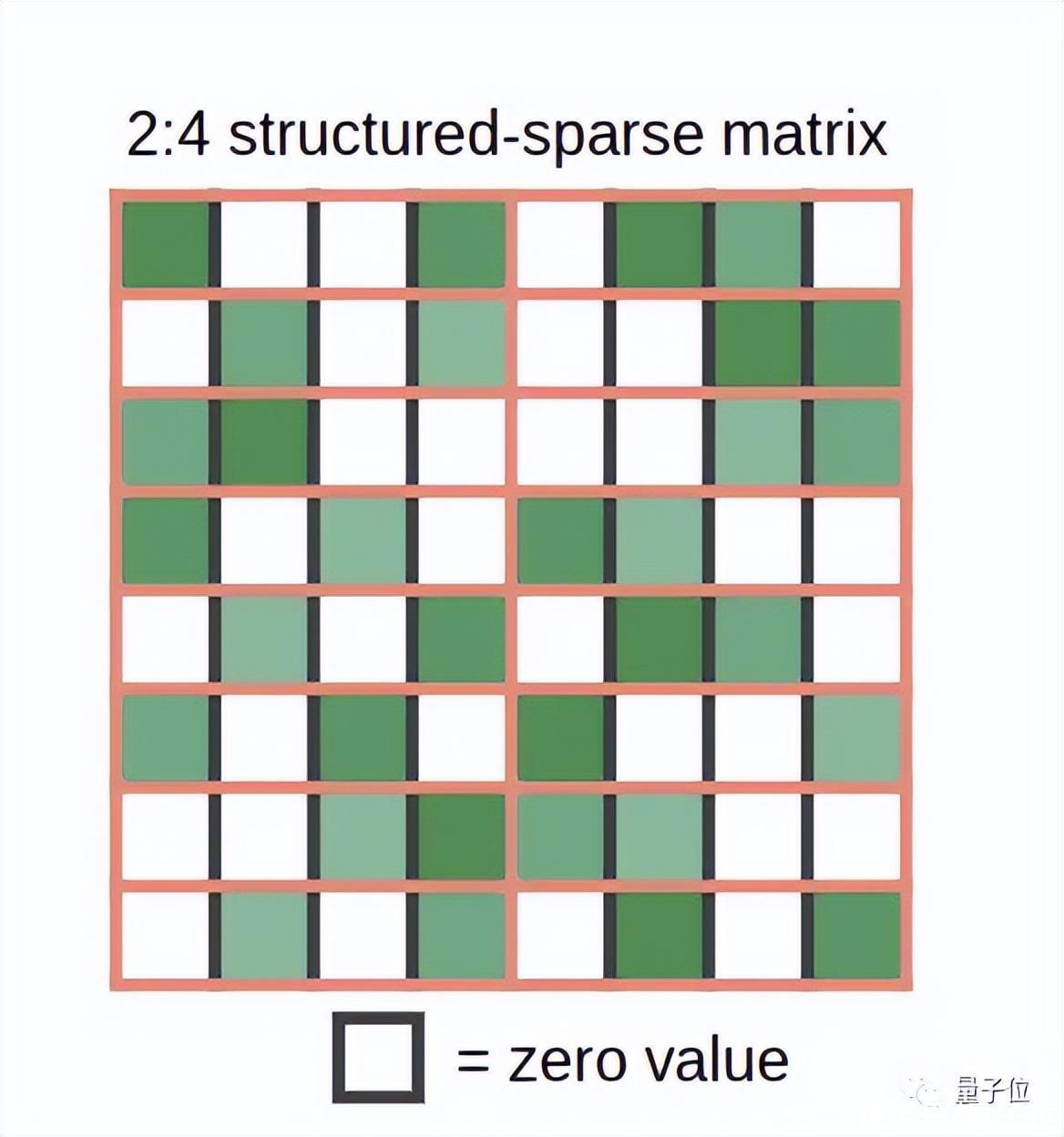
然后把这些稀疏权重矩阵与一些密集输入相乘,Tensor Core功能启动,将稀疏矩阵压缩为密集表示,其大小为下图所示的一半。
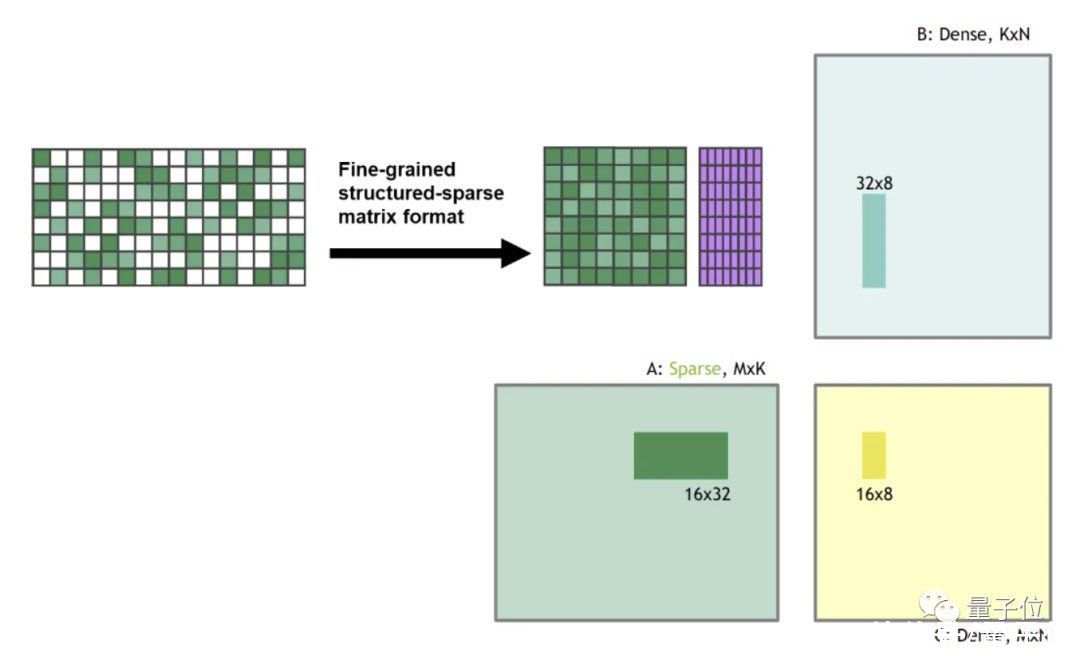
在压缩之后,密集压缩的“碎片”被送入Tensor Core,计算的矩阵乘法是一般大小的两倍。这样,运算速度就成了通常的2倍。
Tim哥表示,上述性能点,他在统计英伟达GPU性能时都考虑在内了。
如果你把这些东西吃透了话,以后就能完全靠自己配置出最合适的“炼丹炉”了。

原文传送门:
https://timdettmers.com/2023/01/30/which-gpu-for-deep-learning/— 完 —
量子位 QbitAI · 头条号签约
","force_purephv":"0","gnid":"97117998399613406","img_data":[{"flag":2,"img":[{"desc":"","height":"264","s_url":"https://p0.ssl.img.360kuai.com/t01c0d3d8e754614008_1.gif","title":"","url":"https://p0.ssl.img.360kuai.com/t01c0d3d8e754614008.gif","width":"630"},{"desc":"","height":"956","title":"","url":"https://p0.ssl.img.360kuai.com/t0185f1484b8ca2ed15.jpg","width":"1332"},{"desc":"","height":"1041","title":"","url":"https://p0.ssl.img.360kuai.com/t01f659874071f48ef2.jpg","width":"1080"},{"desc":"","height":"693","title":"","url":"https://p0.ssl.img.360kuai.com/t01095340ca5cb7cfd2.jpg","width":"1080"},{"desc":"","height":"686","title":"","url":"https://p0.ssl.img.360kuai.com/t0169787f99c9fa167e.jpg","width":"845"},{"desc":"","height":"1052","title":"","url":"https://p0.ssl.img.360kuai.com/t01da482b81567d6029.jpg","width":"1080"},{"desc":"","height":"1248","title":"","url":"https://p0.ssl.img.360kuai.com/t011fa66e523aefd740.jpg","width":"1168"},{"desc":"","height":"656","title":"","url":"https://p0.ssl.img.360kuai.com/t01743c6c7e34b2f694.jpg","width":"1080"},{"desc":"","height":"839","title":"","url":"https://p0.ssl.img.360kuai.com/t01cac7e59511df828c.jpg","width":"980"}]}],"original":0,"pat":"art_src_3,sexf,sex4,sexc,fts0,sts0","powerby":"hbase","pub_time":1677727440000,"pure":"","rawurl":"http://zm.news.so.com/388491c912754fbea2af892aa41f6290","redirect":0,"rptid":"6ef8280751e598ad","rss_ext":[],"s":"t","src":"量子位","tag":[{"clk":"kdigital_1:英伟达","k":"英伟达","u":""},{"clk":"kdigital_1:v10","k":"v10","u":""},{"clk":"kdigital_1:内存","k":"内存","u":""},{"clk":"kdigital_1:gpu","k":"gpu","u":""},{"clk":"kdigital_1:rtx","k":"rtx","u":""}],"title":"2023「炼丹」GPU选购指南来了:英伟达3080和4070Ti成性价比之王
贝翰恒1299求大佬详细介绍华硕海神GTX1080Ti显卡的详细参数? -
宰钓单18174885591 ______ 华硕ROG-POSEIDON-GTX1080TI-P11G-GAMING游戏显卡采用全新Pascal架构的GTX1080Ti核心,核心频率高达1733MHz!搭载352-bit 11GB GDDR5X超大容量显存,是征战5K游戏的神兵利器!经权威测试表明其游戏性能比公版GTX1080Ti...
贝翰恒1299gtx750ti显卡系统 -
宰钓单18174885591 ______ gtx750ti同级 GTX295 A卡 HD5870 R7 260X 仅次于GTX650ti 的一块低端GPU 详细参数 主要参数 适用类型台式机 核心代号GM107 制造工艺28纳米 核心频率1020MHz 显存类型支持DDR5 显存容量2048MB 显存位宽128bit 显存频率5400MHz ...
贝翰恒129912600kf能上40系显卡吗
宰钓单18174885591 ______ 能能跑满“rtx3090ti、rx6900xt、rtx3080ti”.12600kf处理器的性能是溢出于当今显卡的性能的,12600kf需要即将发布的4090显卡才能发挥出全部性能.没有特殊工作需求打游戏用i3 12100kf就够用,办公用5950x就够用,12600kf或者性能更高的处理器只适合预算无限制的人自己diy.
贝翰恒12993080和3070性能差距 -
宰钓单18174885591 ______ 3080显卡比3070显卡强10%. 同样的配置下如果你是2k分辨率,使用3060ti开光追开DLSS可以达到56帧,勉强达到流畅60帧的水准,3070的话比3060ti高6帧,差距不是特别大,如果使用3080就能达到83帧,3090比3080高10帧. 个人觉得...
贝翰恒1299电脑电源750w(电脑电源750w一小时几度电)
宰钓单18174885591 ______ 电脑电源750w一小时几度电对一般用户来说没有差别的 如果您用的CPU特别耗电,... 你说的是850瓦电源简称850w,850w的电源最高可以带3080ti显卡推荐用3080显卡,...
贝翰恒1299显卡索泰GTX1070Ti - 8GD5至尊PLUS和大白鲨GT52?
宰钓单18174885591 ______ 索泰 GTX 1070Ti-8GD5 至尊PLUS和大白鲨GT520 1GB DDR3超值版都有各自的特色和优缺点,就个人而言我是比较喜欢大白鲨GT520 1GB DDR3超值版.下面来看看这...
贝翰恒1299gtx980ti比gtx970强多少 -
宰钓单18174885591 ______ 百分之40
贝翰恒1299三星C7000参数 -
宰钓单18174885591 ______ C7000规格参数,请参考以下介绍: 1.屏幕:5.7英寸Super AMOLED屏幕;分辨率:1080 x 1920 (FHD). 2.外形体积是:156.6 x 77.2 x 6.8mm;重量为169g. 3.外壳颜色:枫叶金、蔷薇粉、皎洁银、烟雨灰(具体以实际销售为准). 4.CPU(处理器):2GHz,八核处理器. 5.内存:总ROM内存为32GB/64GB;总RAM内存为4GB;最大支持128GB Micro SD卡. 6.摄像头:主摄像头1600万像素,前置摄像头800万像素. 7.蓝牙版本:蓝牙4.2. 8.USB采用2.0接口. 9.电池容量3300mAh.
贝翰恒1299影驰GTX1080Ti名人堂和大白鲨HD48601GBDDR5白?
宰钓单18174885591 ______ 影驰GTX 1080 Ti名人堂和大白鲨HD4860 1GB DDR5白金版都有各自的特色和优缺点,就个人而言我是比较喜欢大白鲨HD4860 1GB DDR5白金版.下面来看看这两款显...
贝翰恒1299GTX550Ti显卡是独显吗 -
宰钓单18174885591 ______ 肯定是独立显卡,而且是中端级别的显卡,下面给你参考一下这个显卡的参数: 基本参数 型号 GeForce GTX550Ti 产品定位 中端主流 芯片厂方 NVIDIA 芯片型号 NVIDIA GeForce GTX 550 芯片代号 GF116 制作工艺 40纳米 核心位宽 256bit 显...