batchsize
丰色 发自 凹非寺
量子位 | 公众号 QbitAI
现有大语言模型的训练和推理速度,还能再快一点——
快多少?2-4倍。
各种大模型都在用的FlashAttention今天正式发布第2代并开源,所有Transformer架构的模型都可使用它来加速。
一代方法去年6月发布,无需任何近似即可加速注意力并减少内存占用。
现在,FlashAttention-2将它再度升级,使其核心注意力操作的速度再提高2倍,端到端训练Transformer时的速度再提高1.3倍,并可在英伟达A100上训练时实现72%的模型FLOP利用率(一般模型都在50%上下)。
鉴于现在炼一个大语言模型的成本高达数千万美元,FlashAttention-2这一系列操作直接就能帮我们省掉数百万(美元)!
网友惊得脏话都出来了(狗头):
目前,这个项目已在GitHub上收获4.4k标星。
与此同时,我们注意到,它的一作已经完成斯坦福博士学位并加盟大模型创业公司Together AI。
具体实现
据介绍,一代FlashAttention是一种对注意力计算重新排序的算法,它利用经典方法如tiling(切片)来显著加快计算速度,并将序列长度的内存使用量从二次方减为线性。
其中tiling方法指的是将输入块从HBM(GPU内存)加载到SRAM(快速缓存),然后对该块进行attention操作,再更新HBM中的输出。
对HBM的反复读写就成了最大的性能瓶颈。
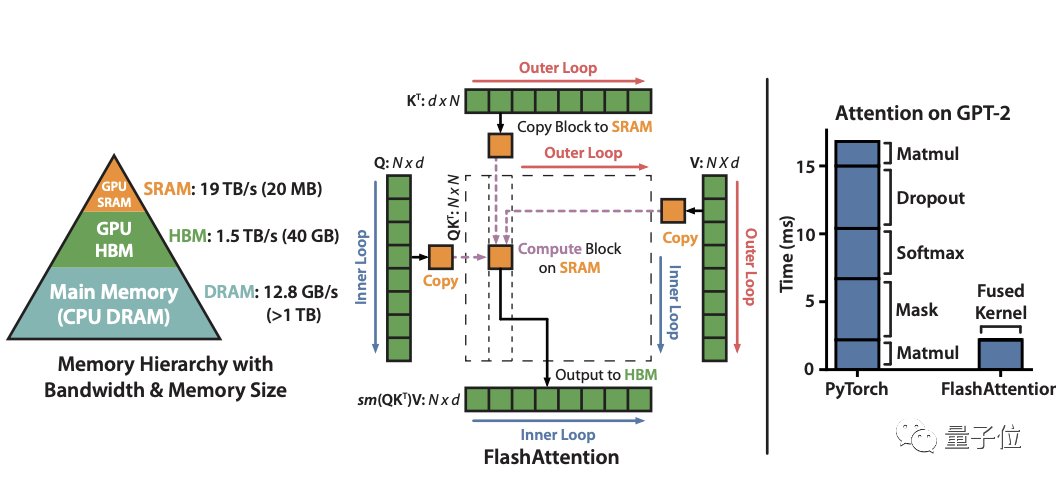
正是这种通过避免将大型中间注意力矩阵写入HBM的方法,FlashAttention减少了内存读/写量,从而带来2-4倍的时钟时间加速。
然而,这个算法仍然存在一些低效率的问题,导致它仍然不如优化矩阵乘法 (GEMM) 运算来得快,最终仅达到理论最大FLOPs/s的25-40%(例如在A100上最多124 TFLOPs/s)。
究其原因,还是因为不同线程块之间的工作和GPU上的wrap划分不理想。
在此,FlashAttention-2进行了三方面的改进。
首先,在基础算法上,减少非matmul(矩阵乘法) FLOP的数量。
一层原因是由于现代GPU具有专门的计算单元,matmul速度更快。例如A100上FP16/BF16 matmul的最大理论吞吐量为312TFLOPs/s,但非matmul FP32的理论吞吐量仅为19.5 TFLOPs/s。
另一层原因是价格考量,毕竟每个非matmul FLOP比matmul FLOP贵16倍。同时在matmul FLOP上花费尽可能多的时间也能保持高吞吐量。
为此,作者重写了FlashAttention中的softmax trick,无需更改输出即可减少重新缩放操作的数量,以及边界检查和因果屏蔽操作(causal masking operation)。
其次,当batch size较小时并行化以获得更高的占用率。
FlashAttention一代在batch size和注意力头数量上进行并行化。
由于它使用1个线程块来处理1个注意力头,总共就有(batch_size*注意力头数)个线程块,每个线程块被安排在流式多处理器 (SM) 上运行。
当在像A100这样有108个SM处理器上操作时,如果线程块很多比如>=80,这样的调度安排就很有效。
而在长序列的情况下,也就是batch size和头数量很少(小)时,就需要在序列长度维度上另外进行并行化来更好地利用GPU上的多处理器了。
这个改进也是FlashAttention-2速度显著提升的一大原因。
最后,改进工作分区。
在线程块内,我们必须确定如何在不同的warp之间划分工作。通常是每个块使用4或8个warp,现在,作者改进了这一方式,来减少不同warp之间的同步和通信量,从而减少共享内存读写操作。
如下图左所示,FlashAttention一代的做法是将K和V分割到4个warp上,同时保持Q可被所有warp访问。这样的后果是所有warp都需要将其中间结果写入共享内存,然后进行同步再将中间结果相加,非常低效,减慢了FlashAttention中的前向传播速度。
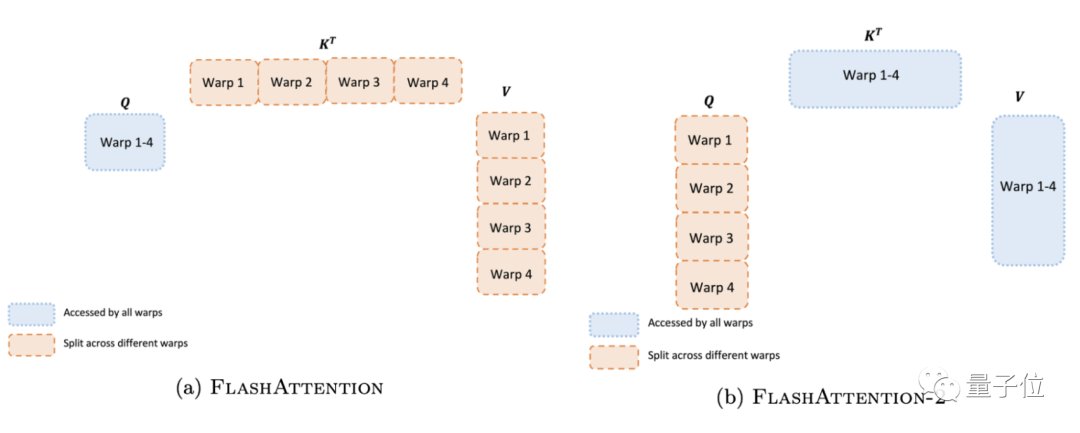
而在FlashAttention-2中,作者将Q分为四个warp,同时保证所有warp都可访问K和V。
每个warp执行矩阵乘法获得Q K^T的切片后,只需与V的共享切片相乘即可获得相应的输出。也就是说warp之间不需要通信,那么共享内存读写操作就少了很多,速度也就提上来了。
除了这三个大改进,FlashAttention-2还有两个小改动:一是注意力头数从128增至256,这意味着GPT-J、CodeGen和CodeGen2以及StableDiffusion 1.x等模型都可以使用 FlashAttention-2来进行加速和内存节省了;
二是支持多查询注意力(MQA)和分组查询注意力(GQA)。
实验评估
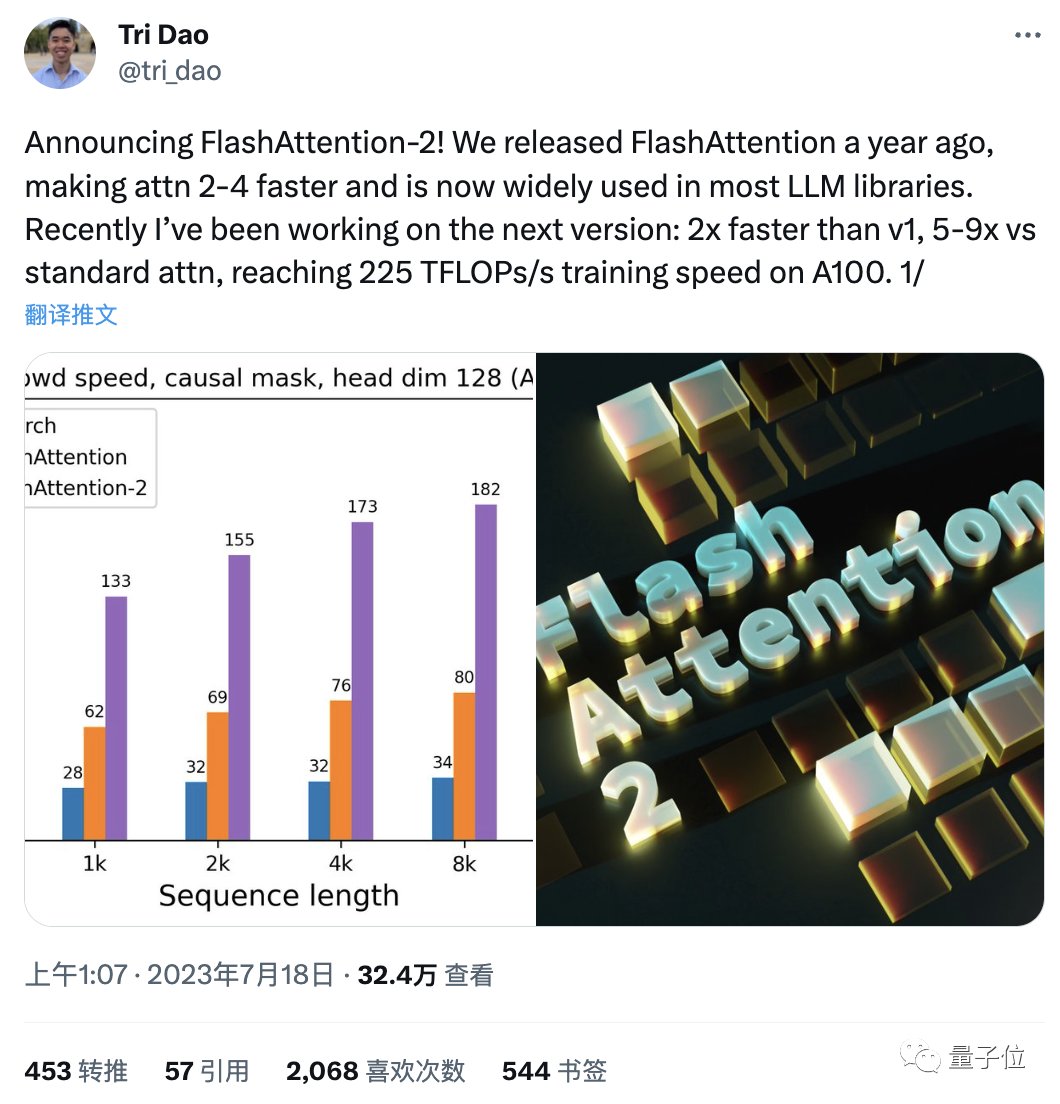
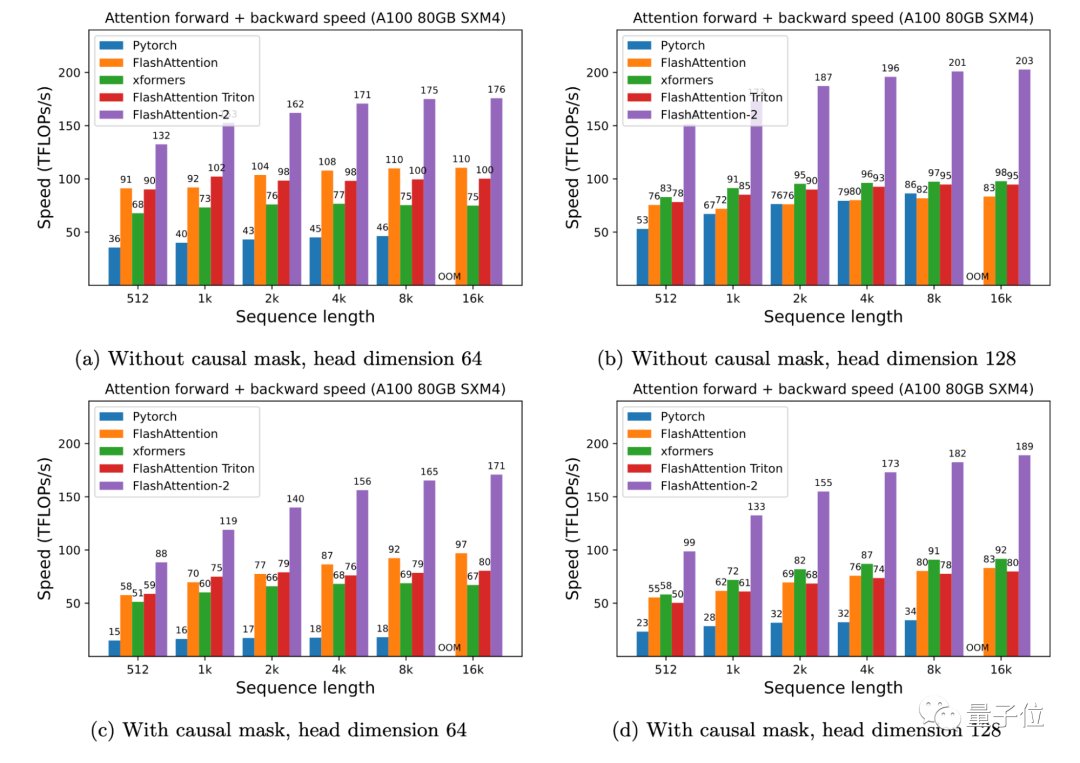
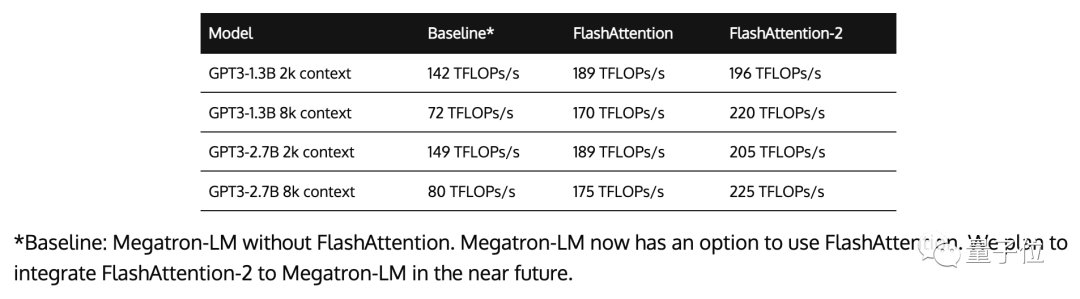
作者在A100 80GB SXM4 GPU上对不同配置(有无causal mask,头数量64或128)下的运行时间进行了测量。
结果发现:
FlashAttention-2比FlashAttention(包括xformers库和Triton中的其他实现)快大约2倍,这也意味我们可以用与之前训练8k上下文模型相同的价格来训练具有16k上下文的模型了(也就是模型上下文长度加倍)。
而与PyTorch中的标准注意力实现相比,FlashAttention-2的速度最高可达9倍。
此外,有了FlashAttention-2,我们只需在H100 GPU上运行相同的实现(不使用特殊指令利用TMA和第四代Tensor Core等新硬件功能),训练速度就可以跑到高达335TFLOPs/s的成绩。
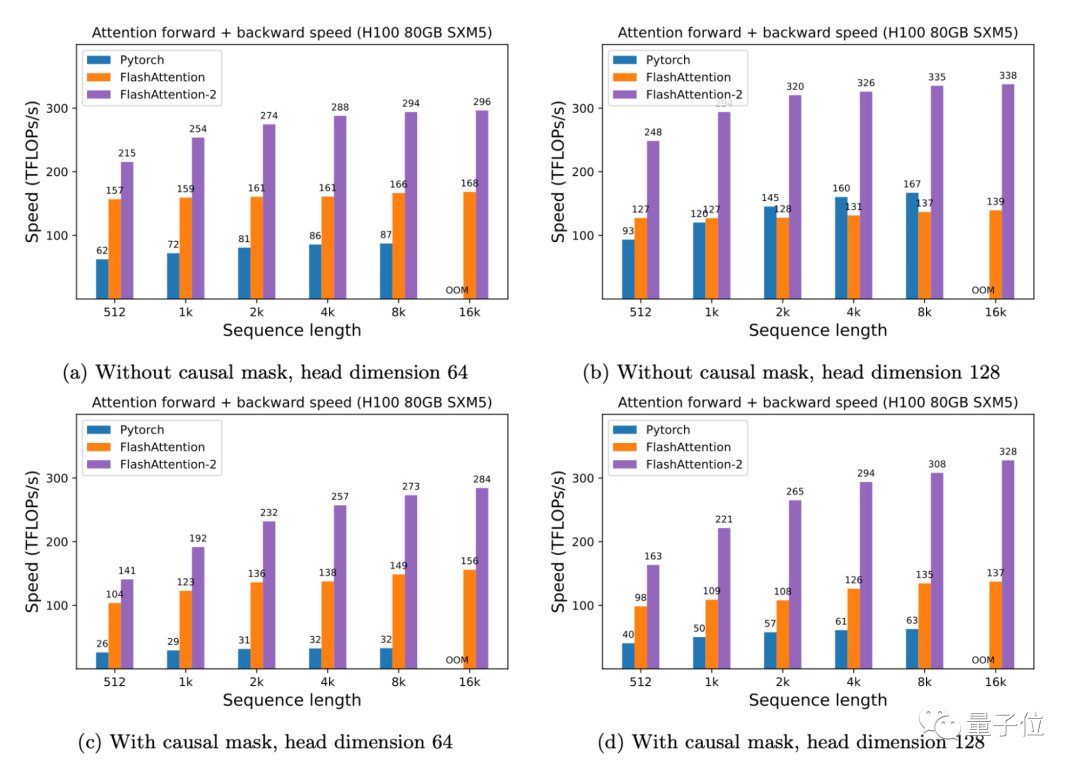
以及当用于端到端训练GPT式模型时,FlashAttention-2还能在A100上实现高达225TFLOPs/s的速度(模型FLOPs利用率达72%)。这与已经优化程序足够高的FlashAttention相比,速度再提高了1.3倍。
一作加入大模型创业公司
FlashAttention-2论文仅显示一位作者:Tri Dao。他也是FlashAttention一代的两位共同作者之一。

据了解,Tri Dao的研究方向为机器学习和系统的交叉领域,去年拿下ICML 2022杰出论文亚军奖。
最近他刚刚获得斯坦福大学计算机科学博士学位,即将上升普林斯顿大学助理教授,并已宣布加盟生成式AI创业公司Together AI(该司主要目标构建一个用于运行、训练和微调开源模型的云平台)担任首席科学家。

One More Thing
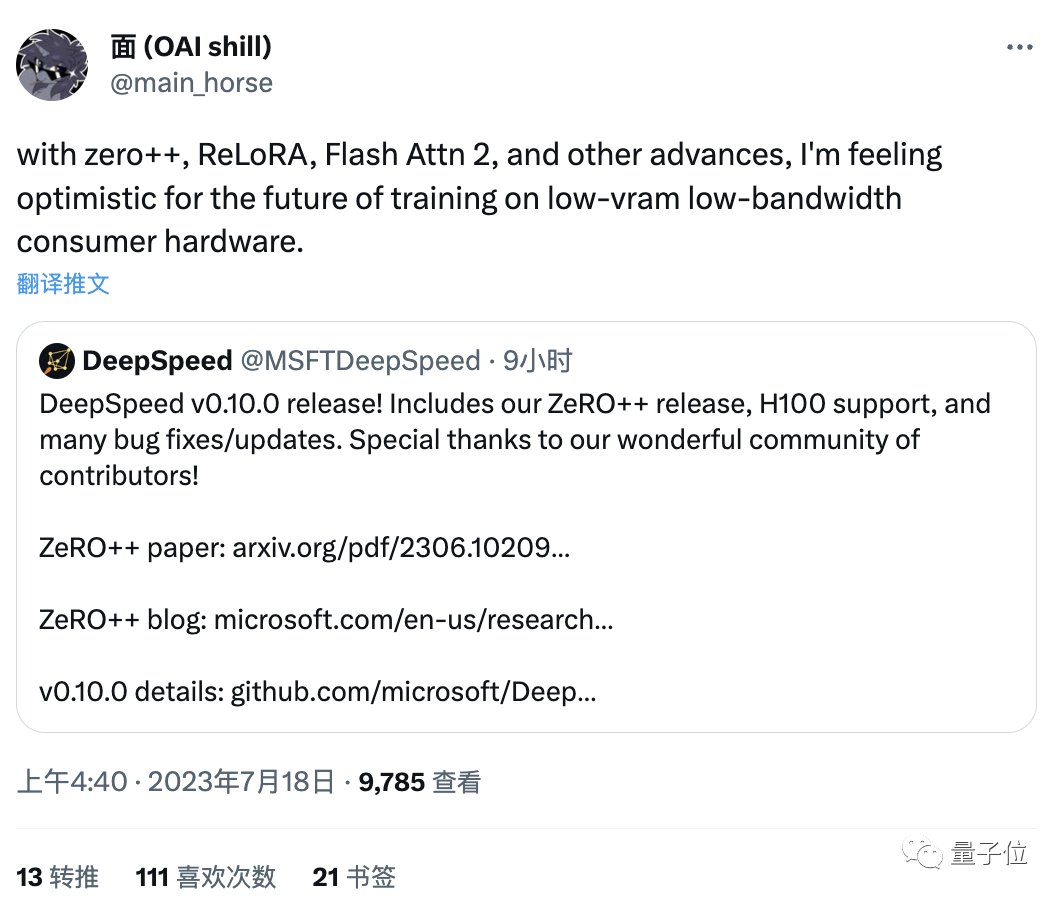
最后,有网友发现,除了FlashAttention-2,最近还有一系列类似成果,包括DeepSpeed的ZeRO++、马萨诸塞大学de ReLoRA。
它们都是用于加速大型模型预训练和微调,这些研究成果让他觉得:
未来在低vram低带宽的消费显卡上训练大模型,似乎已不是在做梦了。
大家认为呢?
论文地址:https://tridao.me/publications/flash2/flash2.pdf
博文地址:https://princeton-nlp.github.io/flash-atttention-2/GitHub主页:https://github.com/Dao-AILab/flash-attention参考链接:[1]https://twitter.com/tri_dao/status/1680987577913065472?s=20[2]https://twitter.com/togethercompute/status/1680994294625337344?s=20[3]https://twitter.com/main_horse/status/1681041183559254017?s=20— 完 —
量子位 QbitAI · 头条号签约
","gnid":"92441181c58b35d9b","img_data":[{"flag":2,"img":[{"desc":"","height":"1104","title":"","url":"https://p0.ssl.img.360kuai.com/t0188a3b07458fd6014.jpg","width":"1060"},{"desc":"","height":"646","title":"","url":"https://p0.ssl.img.360kuai.com/t017e406e12f659d0f8.jpg","width":"1080"},{"desc":"","height":"516","title":"","url":"https://p0.ssl.img.360kuai.com/t011bcc410837811bd8.jpg","width":"1060"},{"desc":"","height":"529","title":"","url":"https://p0.ssl.img.360kuai.com/t01bbfebb26288749f3.jpg","width":"1080"},{"desc":"","height":"484","title":"","url":"https://p0.ssl.img.360kuai.com/t01bfd3914ddf03e03f.jpg","width":"1056"},{"desc":"","height":"433","title":"","url":"https://p0.ssl.img.360kuai.com/t01ade921308e8fdd1a.jpg","width":"1080"},{"desc":"","height":"763","title":"","url":"https://p0.ssl.img.360kuai.com/t014f08891dacfb345a.jpg","width":"1080"},{"desc":"","height":"772","title":"","url":"https://p0.ssl.img.360kuai.com/t010335c671da1d9ce2.jpg","width":"1080"},{"desc":"","height":"299","title":"","url":"https://p0.ssl.img.360kuai.com/t01ec1e5cb5243138be.jpg","width":"1080"},{"desc":"","height":"377","title":"","url":"https://p0.ssl.img.360kuai.com/t01835eb987c50a7041.jpg","width":"1080"},{"desc":"","height":"811","title":"","url":"https://p0.ssl.img.360kuai.com/t01d58548cb24c18359.jpg","width":"1080"},{"desc":"","height":"900","title":"","url":"https://p0.ssl.img.360kuai.com/t012b47f5f43a1993f6.jpg","width":"1062"}]}],"original":0,"pat":"art_src_3,fts0,sts0","powerby":"hbase","pub_time":1689656220000,"pure":"","rawurl":"http://zm.news.so.com/aaa740b50f2c7989120d5a99e5c64227","redirect":0,"rptid":"6193a91eeccb8a2f","rss_ext":[],"s":"t","src":"量子位","tag":[{"clk":"kdigital_1:twitter","k":"twitter","u":""},{"clk":"kdigital_1:斯坦福","k":"斯坦福","u":""},{"clk":"kdigital_1:gpu","k":"gpu","u":""}],"title":"让Transformer大模型训练速度再快两倍!斯坦福博士独作
鱼兔红3992如何用深度学习进行CT影像肺结节探测(附 -
施彬邱13968657205 ______ 1.数据预处理 首先用SimpleITK把mhd图片读入,对每个切片使用Gaussian filter然后使用阈值-600把肺部图片二值化,然后再分析该切片的面积,去掉面积小于30mm2的区域和离心率大于0.99的区域,找到3D的连通区域. 只保留0.68L到8.2L体...
鱼兔红3992如何优化hibernate框架的使用 -
施彬邱13968657205 ______ 初用HIBERNATE的人也许都遇到过性能问题,实现同一功能,用HIBERNATE与用JDBC性能相差十几倍很正常,如果不及早调整,很可能影响整个项目的进度. 大体上,对于HIBERNATE性能调优的主要考虑点如下: * 数据库设计调整 * ...
鱼兔红3992sqlbulkcopy的batchsize属性设为10000,如果不足会报错吗 -
施彬邱13968657205 ______ SqlBulkCopy的BatchSize的问题 [问题点数:100分] ...然后循环dt.Rows.Count,把10000笔申请的Batch循环输出...如是商业用途请联系原作者....
鱼兔红3992如何在程序中调用Caffe做图像分类 -
施彬邱13968657205 ______ Caffe是目前深度学习比较优秀好用的一个开源库,采样c++和CUDA实现,具有速度快,模型定义方便等优点.学习了几天过后,发现也有一个不方便的地方,就是在我的程序中调用Caffe做图像分类没有直接的接口.Caffe的数据层可以从数据...
鱼兔红3992keras 如何输出softmax分类结果属于某一类的概率 -
施彬邱13968657205 ______ softmax是用于单标签输出,模型训练后,调用model.predict函数就可以输出结果为[0.5,0.4,0.1](输出数量为最后一层隐藏层的neuron数)这样的矩阵,里面即为你所需的预测概率值,值得注意的是,softmax会限制输出的所有概率相加为1. 如果需要预测的是多个标签而不是单个标签,则需要使用sigmoid作为输出激活函数,那么输出就不再强制相加为1,可以得到每个分类的实际预测值,此时只需要设置一个致信的threshold则可以得到多个分类预测值. 每个激活函数的详细解释看这里网页链接
鱼兔红3992sqlserver sqlbulkcopy.batchsize设置多少合适 -
施彬邱13968657205 ______ C#:用SqlBulkCopy来实现批量插入数据 VB也应会有这个类SqlBulkCopy SqlBulkCopy是.net2.0的新特性,平时用的很少,但是其功能却是非常强大,对于批量插入数据性能非常优越 代码 /// <summary> /// bulk插入 /// </summary> private void ...
鱼兔红3992如何制定检索策略? -
施彬邱13968657205 ______ 类级别检索策略有立即检索和延迟检索,默认的检索策略是立即检索.在Hibernate映射文件中,通过在<class>上配置lazy属性来确定检索策略.对于Session的检索方式,类级别检索策略仅适用于load方法;也就说,对于get、qurey检索,持久...
鱼兔红3992如何高效地批量导入数据到SqlServer -
施彬邱13968657205 ______ 2.SqlBulkCopy是个不错的选择,直接由DataTable可以导入到数据库 ,但要注意(1)列名与目标表一致(2)数据类型一致(3)空值容错处理,参考代码:///<summary///将<see cref="DataTable"/ 的数据批量插入到数据库中.///</summary///...
鱼兔红3992matlab deeplearning toolbox 中的DBN输入数据必须是(0,1]范围内的吗? -
施彬邱13968657205 ______ 程序如下: function [nn, L] = nntrain(nn, train_x, train_y, opts, val_x, val_y) %NNTRAIN trains a neural net % [nn, L] = nnff(nn, x, y, opts) trains the neural network nn with input x and % output y for opts.numepochs epochs, with minibatches of size % ...