gpu+benchmark天梯图
允中 发自 凹非寺
量子位 | 公众号 QbitAI
北京时间11月10日,全球权威AI训练性能基准测试MLPerf Training v2.1结果正式公布[1]。百度使用飞桨框架提交的8机64卡配置下的BERT模型训练性能,位列同等GPU配置下世界第一。端到端训练时间和训练吞吐两个指标均超越NVIDIA高度优化的NGC PyTorch框架。
MLPerf是全球影响力最广的AI性能基准测试之一[2],飞桨本次夺魁,进一步体现了飞桨框架在分布式训练性能上的领先优势。
飞桨在MLPerf Training中的表现成绩
在今年6月30日发布的v2.0榜单里[3],百度飞桨在8卡NVIDIA GPU(400W功耗,80G显存)配置下,BERT模型训练性能排名第一,比其他提交结果快5%~11%不等,展示了飞桨领先的单机多卡并行训练性能优势。
在v2.0优异性能的基础上,飞桨在v2.1中提交的多机性能结果,进一步印证了分布式训练的极致性能表现。图1展示了v2.1中8机64卡NVIDIA GPU(400W功耗,80G显存)配置下BERT模型的所有训练性能数据(共4组),百度飞桨的端到端训练收敛时间比其它提交结果快1%~20%不等;图2展示了图1各组提交数据的吞吐对比,百度飞桨的训练吞吐比其他提交结果快2%~12%不等。
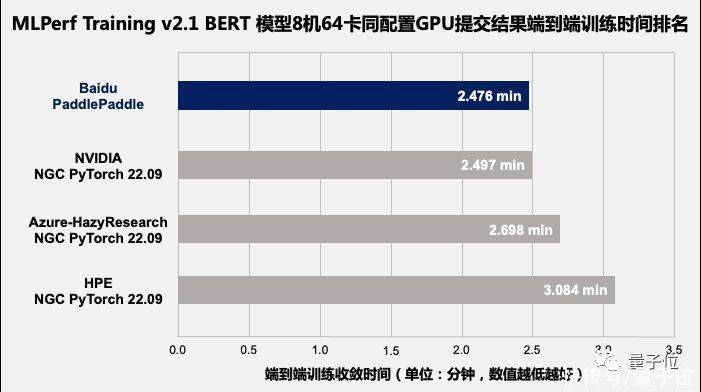
△图1:MLPerf Training v2.1 BERT模型,端到端训练收敛时间排名(8机64卡GPU)[1]
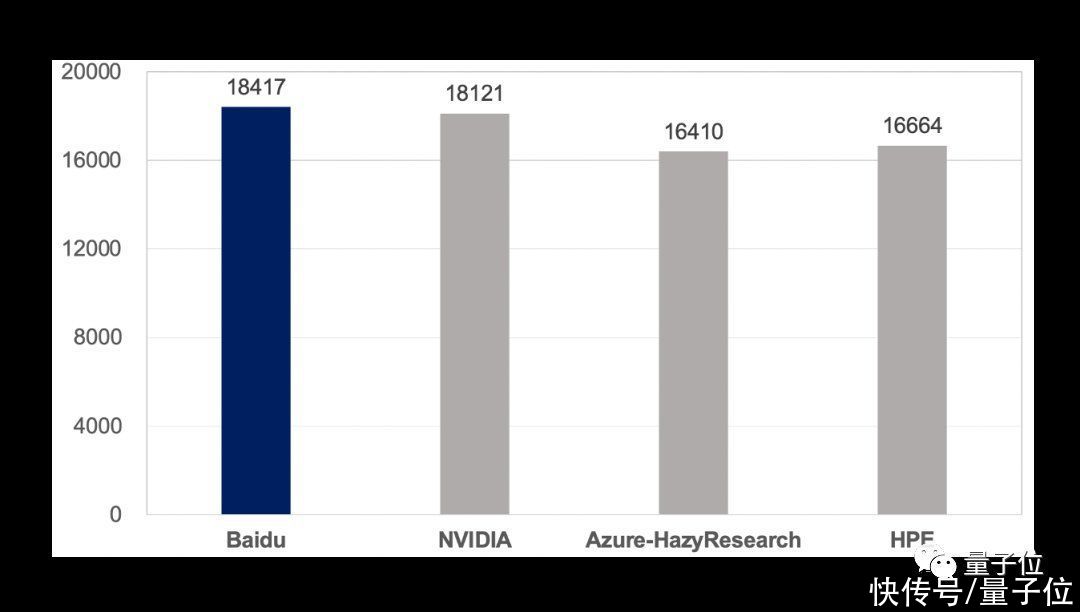
△图2:MLPerf Training v2.1 BERT模型,所有提交结果吞吐比较(8机64卡GPU)[1]
飞桨分布式训练核心技术解析及在MLPerf中的应用
飞桨在MLPerf基准测试中取得的优异成绩,得益于飞桨框架在分布式训练核心技术上的持续探索和创新:
高加速比的混合并行技术
针对大规模稠密参数模型高效训练问题,飞桨在业内首创4D混合并行训练策略。MLPerf BERT模型训练任务基于飞桨的混合并行策略,在单机8卡场景实现了超线性加速,在8机64卡相对于单机的扩展效率达到了94%。
端到端自适应分布式训练技术
针对分布式训练调优困难的问题,飞桨提出了端到端自适应分布式训练架构。对于MLPerf BERT模型训练任务,根据集群通信拓扑特点并结合NCCL SHARP协议,使用全局通信与分层次通信结合的方式降低整体通信耗时,有效提升模型训练性能。
高效的异构设备负载均衡技术
针对分布式训练经常出现的负载不均、数据加载速度瓶颈等问题,飞桨提出了异构设备混合负载均衡的方案,根据不同设备的算力特点,高效地进行负载均衡设计。MLPerf BERT模型训练任务通过使用GPU高带宽通信,解决模型训练启动时的数据加载慢问题;通过CPU异构设备通信,实现模型训练过程与数据负载均衡间的重叠,提高模型训练效率。
针对分布式训练经常出现的负载不均、数据加载速度瓶颈等问题,飞桨提出了异构设备混合负载均衡的方案,根据不同设备的算力特点,高效地进行负载均衡设计。
MLPerf BERT模型训练任务通过使用GPU高带宽通信,解决模型训练启动时的数据加载慢问题;通过CPU异构设备通信,实现模型训练过程与数据负载均衡间的重叠,提高模型训练效率。
源自产业实践飞桨分布式技术助力大模型落地
作为产业级深度学习平台,飞桨的分布式训练技术在实践中不断创新,并结合应用反馈持续优化。结合计算机视觉、自然语言处理、科学计算等领域的应用,飞桨研发了异构硬件下的低存储和高性能训练技术,相继发布了业界首个通用异构参数服务器架构、4D混合并行训练策略、端到端自适应分布式训练架构等多项领先技术成果。
飞桨大规模分布式训练技术,支持了百度大模型领域技术快速迭代持续领先。例如,百度发布了全球首个知识增强千亿大模型“鹏城-百度·文心”、全球首个百亿参数中英文对话预训练生成模型PLATO-XL、全球规模最大中文跨模态生成模型ERNIE-VILG、业界规模最大的多任务统一视觉大模型VIMER-UFO。
此外,飞桨分布式技术还在国产硬件集群上将AlphaFold2千万级别蛋白initial training阶段从7天压缩到2.6天。目前,文心已发布20多个大模型,覆盖自然语言处理、计算机视觉、跨模态、生物计算等领域,赋能工业、能源、城市、金融等千行百业。
结语
继在MLPerf Training v2.0获得了BERT模型单机训练性能世界第一后,飞桨在MLPerf Training v2.1的8机64卡配置下分布式训练性能再度折桂。成绩的背后,不仅是飞桨分布式框架的持续创新突破,也伴随着硬件生态的蓬勃发展。
飞桨硬件生态伙伴体系历经“共聚”、“共研”、“共创”三大阶段,目前已携手超过30家硬件厂商深度融合优化。飞桨与NVIDIA、Intel、瑞芯微、Arm等多家伙伴厂商合作,结合自有软硬件基础开发栈特色,针对不同应用场景和产品,在共同推出飞桨生态发行版、建设开源开放模型库、开发课程与培训内容等方面开展合作。
比如,NVIDIA与飞桨合作推出了NGC飞桨镜像,自2022年5月26日上线以来每月更新,持续不断地将NVIDIA CUDA最新软件栈与飞桨框架深度集成。NVIDIA与百度飞桨联合打造了深度学习优化与部署课程,预计12月中旬在百度飞桨人工智能学习与实训社区(AI Studio)及NVIDIA 深度学习培训中心 (DLI) 同步上线。
未来,飞桨将继续在软硬协同性能优化和大规模分布式训练技术等方向持续创新,为广大用户提供广泛适配、性能优异的产业级深度学习平台。
参考文献:
[1] MLPerf Training v2.1 Resultshttps://mlcommons.org/en/training-normal-21/
[2] THE NEXT PLATFORMhttps://www.nextplatform.com/2021/08/10/why-the-mlperf-benchmark-is-good-for-ai-and-good-for-you/[3] MLPerf Training v2.0 Resultshttps://mlcommons.org/en/training-normal-20/[4] 飞桨框架v2.3发布高可复用算子库PHI!重构开发范式,降本增效https://www.paddlepaddle.org.cn/support/news?action=detail&id=2994[5] 飞桨框架v2.3一键开启全自动性能优化,媲美专家级优化效果https://www.paddlepaddle.org.cn/support/news?action=detail&id=3079— 完 —
量子位 QbitAI · 头条号签约
","force_purephv":"0","gnid":"97e628da31db9c7b8","img_data":[{"flag":2,"img":[{"desc":"","height":"392","title":"","url":"https://p0.ssl.img.360kuai.com/t018c856e3bc66afe10.jpg","width":"701"},{"desc":"","height":"612","title":"","url":"https://p0.ssl.img.360kuai.com/t01b3ce965cf07d172b.jpg","width":"1080"}]}],"original":0,"pat":"pdc,art_src_3,fts0,sts0","powerby":"hbase","pub_time":1668142500000,"pure":"","rawurl":"http://zm.news.so.com/b6a086e051266b6f37ae27d918870e02","redirect":0,"rptid":"89d866ebeb6aceb2","s":"t","src":"量子位","tag":[{"clk":"ktechnology_1:rain","k":"rain","u":""},{"clk":"ktechnology_1:gpu","k":"gpu","u":""}],"title":"MLPerf排名榜刷新:相同GPU配置训练BERT,飞桨拿下世界第一
上侨武4385比特币如何找? 昨天无意看到比特币一词,百科了一下也是模模糊糊,谁能给解释一下?现在如果用GPU+ -
高皆瑗17892487026 ______ 比特币不是找出来的,是”挖“出来的,有点类似于黄金,有时成为比特币金.比特币数量总共2100万个,现在挖出来1300多万了吧.比特币目前一个价格大约800左右.挖矿(获取比特币的方式),现在一般人基本上不可能了.从曾经cpu挖矿,到gpu显卡挖矿,到现在的asic挖矿(专业挖矿集成电路),挖矿效率嗖嗖的暴涨.个人挖到,基本就不可能了.比特币创建于2009年,目前扔是个新生事物.未来未知,建议最好还是别涉足了.
上侨武4385骁龙8+4g处理器怎么样 -
高皆瑗17892487026 ______ 骁龙8+4g处理器怎么样1. 概述骁龙8+4g处理器是高通公司最新推出的一款处理器,于2021年3月发布.该处理器采用8个Kryo 680内核和4个Kryo 660内核,性能强大,能够运行多个任务.骁龙8+4g处理器还配备了Adreno 660 GPU,支持5G网...
上侨武4385小米青春版的cpu+gpu架构是什么意思和华为荣耀单核1.5有什么区别 -
高皆瑗17892487026 ______ 架构决定了CPU的性能! 打个比方吧A8和A9架构的CPU就如同 电脑上奔腾和酷睿的差别~ 你说同样是2.4G的频率奔腾强还是酷睿?肯定是酷睿啦 小米就是A8的架构,本来只能用在单核上的,它非搞哥双核,性能只能说比单核好,比起A9的双核那就差远了,功耗还更大!荣耀是1.4G单核 两个手机选的话建议买荣耀,1.4G的最强单核已经能很流畅运行所有游戏了,小米除了CPU比荣耀强一点点,其他做工质量,外观手感,摄像头都比荣耀差一大截!
上侨武4385双核cpu+四核GPU 什么意思 -
高皆瑗17892487026 ______ 恩一看就知道了. 双核CPU是处理器是双核心的, 四核GPU GPU是显卡加速用的,4核的表示显卡速度更快. 其实通俗的说法是双核四显. 不过现在普遍已经出现四核八显的,虽然双核四显家用足够,如果楼主追求平板电脑速度,可以考虑买四核八显的.
上侨武4385显卡芯片NVIDIA GeForce GT 745M+Intel GMA HD 4600 怎么样 -
高皆瑗17892487026 ______ GeForce GT 745M独立显卡属于性能级移动显卡定位,它应用了开普勒显卡架构设计,并支持NVIDIA GPU Boost 2.0和NVIDIA Optimus技术.其将流处理器为384个,核心频率较对位的GT 650M有所提高,就相当于是他的超频版,玩游戏的话现在市面上的主流游戏都没有鸭梨的.
上侨武4385麒麟950GPU能达到高通什么水平 -
高皆瑗17892487026 ______ 麒麟950是第一款16nm FF+的SoC,4*A72+4*A53,性能即便是目前在处理器里面依然是顶级水平,单核性能略逊骁龙820,多核反超820,CPU部分没有黑点.因为海思麒麟祖传的Mali T628 MP4,游戏性能一直是海思SoC的短板,这一代我们终于迎来了新的GPU——Mali T880 MP4,性能达到了原先的两倍,但是还不是顶尖水平,用高通来类比,应该能接近805的Adreno 420,当然也达不到820的Adreno 530,而且也略逊于7420的T760 MP8,怎么说呢,GPU确实拖后腿了,但是总归是不妨碍用,性能也够.总而言之,950是颗性能强悍,功耗出色的好芯片
上侨武4385用的独显,没用核显,为什么鲁大师显示GPU有使用20%+ -
高皆瑗17892487026 ______ 独立显卡也算GPU.计算机的一切显示工作都要GPU来完成.
上侨武4385ATTO+Disk+Benchmark 测速懂看的帮看看
高皆瑗17892487026 ______ 速度真够低的kingmax 16g tf c6 写20m 读 30m 卡看写入速度,看c几没用,kingmax c10 还没c6快!
上侨武4385暴风影音里如何开启GPU硬解码? -
高皆瑗17892487026 ______ 开启gpu硬解码需要你的显卡支持某项编码的硬解码才行,打开暴风,在窗口内右键选高级选项,点选高清,勾选开机高清硬件加速,下面现实的是你的硬件支持的高清编码格式,也就是你的显卡能硬解码的视频格式,勾选智能选择就好了.