spss缺失值处理方法

毕业论文写作在选择数据分析方法时,我们需要考虑以下几个因素:
1、研究目的与问题:我们需要明确研究的目的和要解决的问题,从而确定需要使用哪些指标和统计方法。
2、数据类型与特点:我们需要了解数据的类型、特点以及分布情况,以便选择合适的方法。3、数据的可靠性与完整性:我们需要确保数据的准确性和完整性,以便得出正确的结论。4、方法的可行性:我们需要选择可操作性强、易于实现的方法,以确保分析的可行性和效率。接下来分别进行说明。
当我们在进行毕业论文的数据分析时,研究目的和问题是非常重要的因素。它们不仅决定了我们的研究方向和重点,还直接影响了我们选择的数据分析方法和后续的结果解读。
在论文写作过程中,需要时刻明确自己的研究目的与研究问题是什么,这样才不至于在写论文过程中,越写越偏离主题(避免跑题)。
1、研究目的
研究目的通常是一个宏观的目标,它是对我们想要解答的问题的总体描述。例如,我们的研究目的可能是探究某一变量对消费行为的影响因素研究,或者考察某一项政策对某一社会群体的影响等。
在本科生毕业论文写作过程中,一些比较常见的研究目的包括差异研究、影响因素研究、指标体系构建、问卷调查研究、预测模型、满意度研究、现状类研究、试验设计等。
下面是各大研究目的下常用的一些大的研究方法:
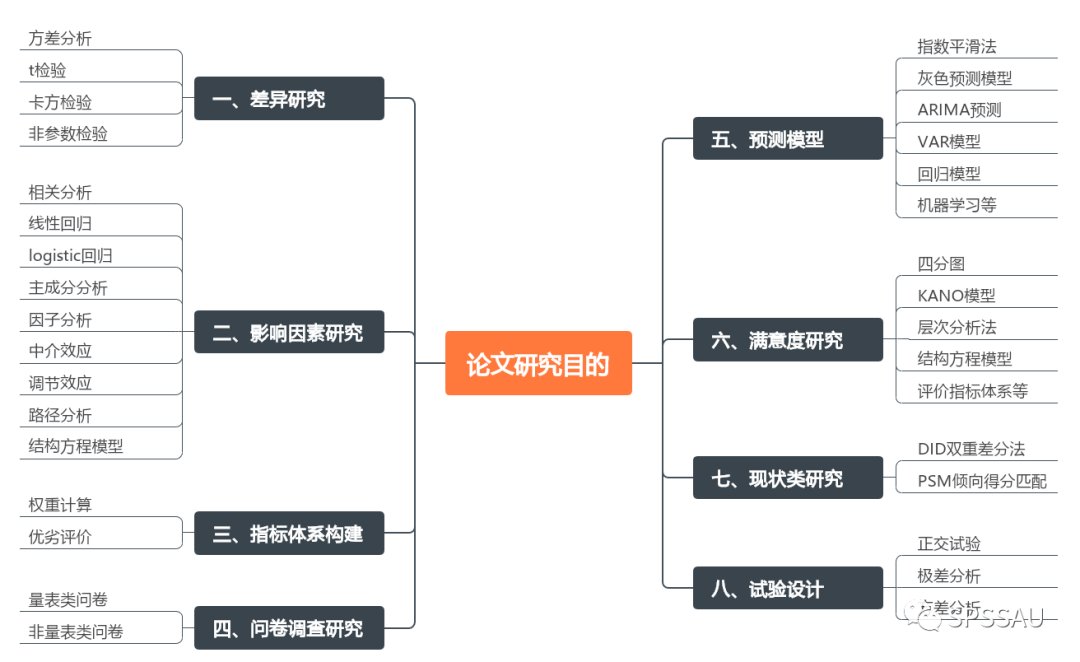
其中影响因素研究是历年论文写作中研究最多的,原因可能在于这种类型的研究在各种领域都非常普遍,所以可进行研究的内容就很多。同时研究影响因素的相关方法都比较简单,模型也比较清晰易懂,对于第一次写毕业论文的同学比较友好。
2、研究问题
研究问题则是研究目的的具体化,它通常以疑问句的形式出现,用以引导我们进行数据分析。一个大的研究目的会对应很多个小的研究问题,尤其是最开始拿到数据时,都会先进行基本的描述分析,掌握数据基本特征,为后续分析做铺垫。
例如,我们的一个小的研究问题可能是:“不同收入水平人群的消费水平是否有差异?”那么对应的我们就应该使用卡方检验进行差异性分析。对应上面讲到的一些研究目的,将方法进行展开介绍。
一、差异研究
常见的差异关系研究方法包括方差分析、t检验、卡方检验、非参数检验。
二、影响因素研究
相关分析常在回归模型分析前使用;线性回归和logistic回归分别对应不同类型Y进行回归模型分析;主成分分析和因子分析常用于信息浓缩和数据降维;中介效应和调节效应是基于回归模型进行更深层次研究;路径分析和结构方程模型用于研究多个潜变量之间的影响关系,对于模型的结构有很高的要求。
三、指标体系构建
毕业论文中评价指标体系构建包括两大部分内容,分别是权重计算和优劣评价。其中权重计算方法最常用的为AHP层次分析法和熵值法,优劣评价中TOPSIS法和模糊综合评价比较常用。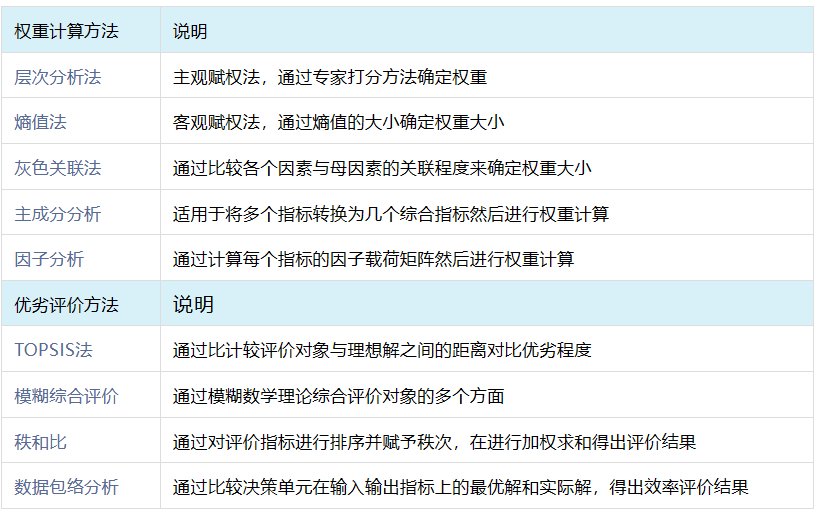
四、问卷调查研究
问卷调查研究类通常分为两大类:量表类问卷和非量表类问卷,分析思路框架:

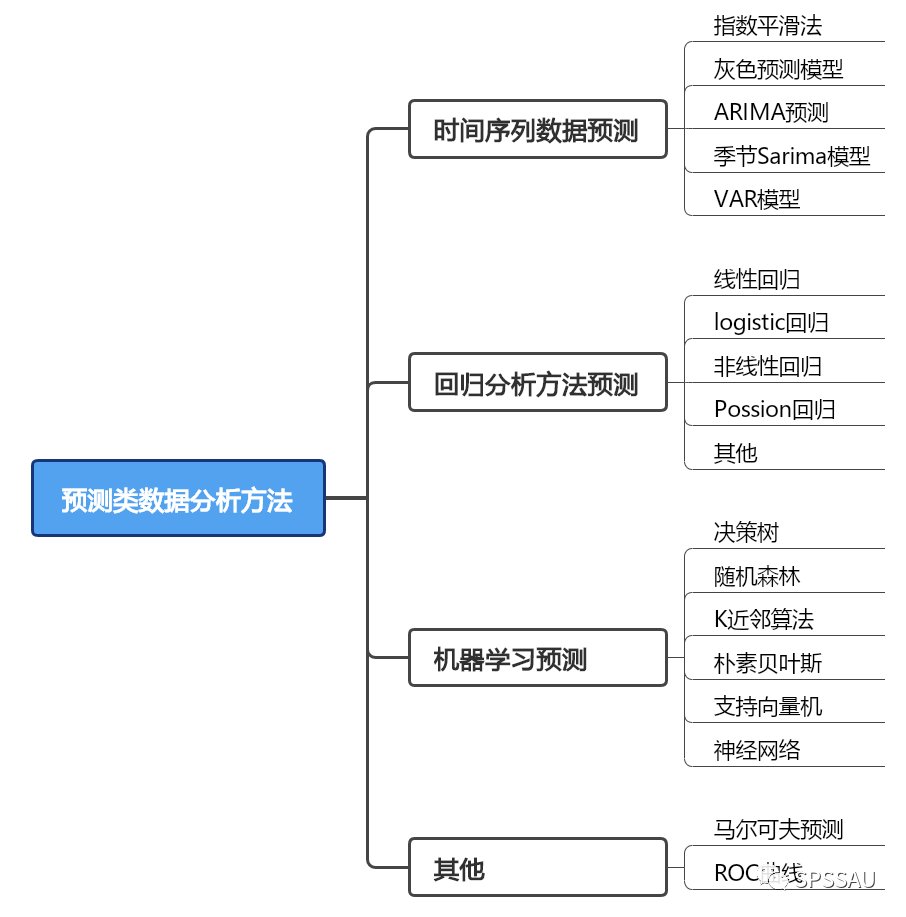
五、预测模型
预测类模型常用有三大类:时间序列类预测方法,如指数平滑法和灰色预测模型;回归类预测方法,包括线性回归、logistic回归、非线性回归等,它们通过建立数学模型来预测数值结果;机器学习类预测方法,如决策树、随机森林和神经网络等。
六、满意度研究
满意度研究通常涉及收集和分析客户对产品或服务的反馈,以了解客户的需求和期望,评估产品或服务的质量和满足客户需求的能力,以及提出改进产品或服务的建议。常用的方法有四分图(象限图)、KANO模型、层次分析法、结构方程模型、评价指标体系构建等。
七、现状政策类研究
双重差分法是一种政策效应评估方法,它通过比较政策实施前后的变化来评估政策对目标群体或更广泛社会的影响。倾向得分匹配是一种用于处理选择性偏差的技术,它通过匹配控制组和实验组样本的方式,模拟一个无偏估计的实验结果,二者常用于政策评估。
八、试验设计
试验研究常通过正交试验的过程希望得到一个最优试验组合,使得目标结果最大或者最小。该过程可以使用极差分析或者方差分析得到最优试验组合。其中极差分析为直观分析法,简单易懂,方便快捷,但是不涉及变量显著性分析,如果要分析变量显著性及在何种水平上显著,应该使用多因素方差分析。
数据类型是每类分析方法的基石,区分好数据类型,便可找到合适的分析方法。
1、数据类型辨析
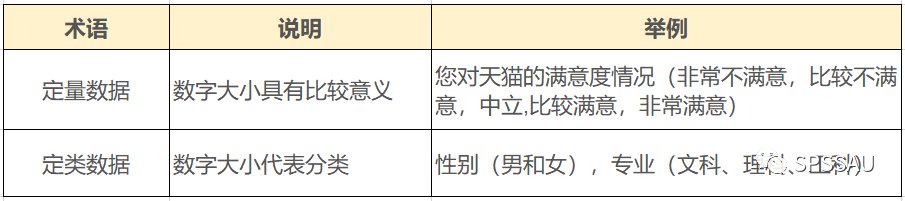
通常来讲,数据可分两大类——定量数据和定类数据。区分好这两类数据,在SPSSAU中即可定位到合适的数据分析方法。二者的区别在于数字大小是否具有比较意义。
定量数据:数字有比较意义,比如数字越大代表满意度越高,量表为典型定量数据。
定类数据:数字无比较意义,比如性别,1代表男,2代表女。
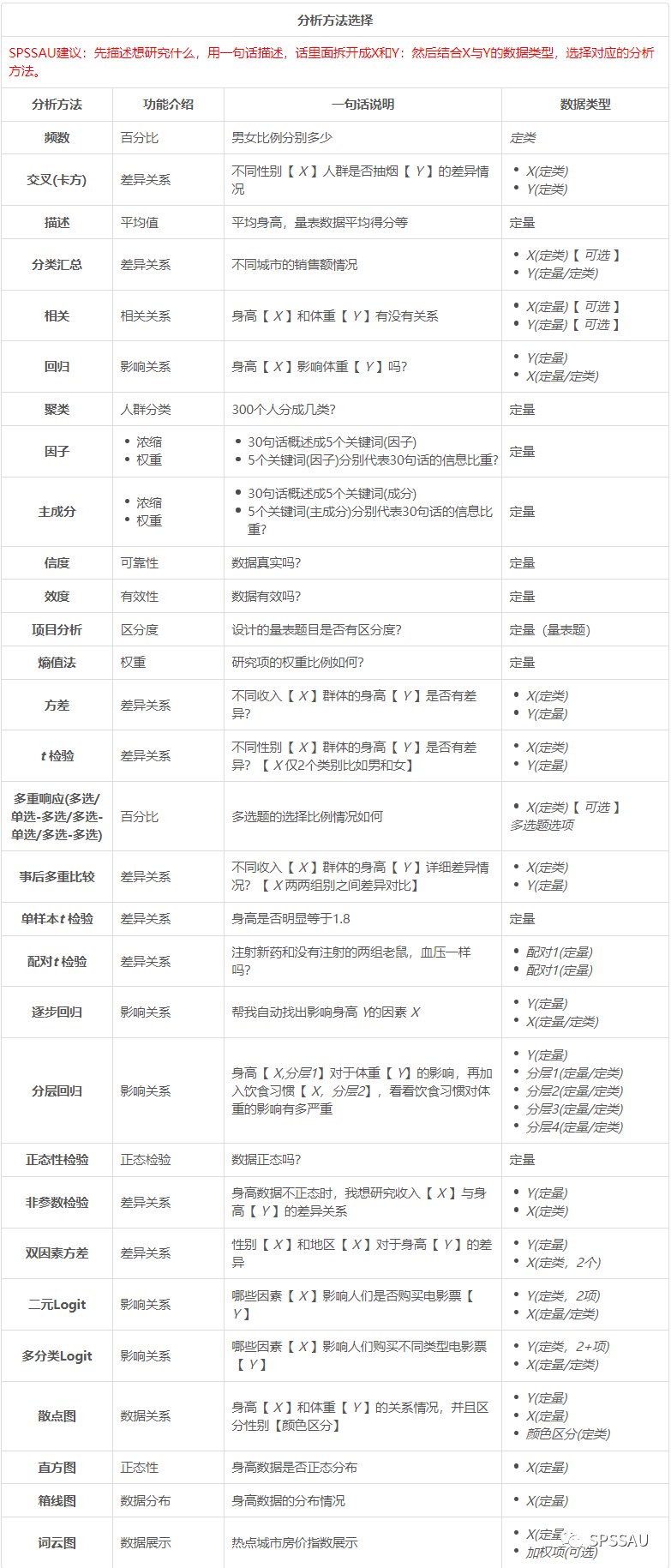
2、分析方法选择
SPSSAU建议:先描述想研究什么,用一句话描述,话里面拆开成X和Y,然后结合X与Y的数据类型,选择对应的分析方法。下面是一些比较常用的分析方法选择说明。
在选择数据分析方法时,我们需要考虑数据的可靠性和完整性。如果数据存在缺失值、异常值将会对分析结果产生不良影响。因此,我们需要进行数据清洗和预处理,以确保数据的准确性和完整性。
1、异常值处理
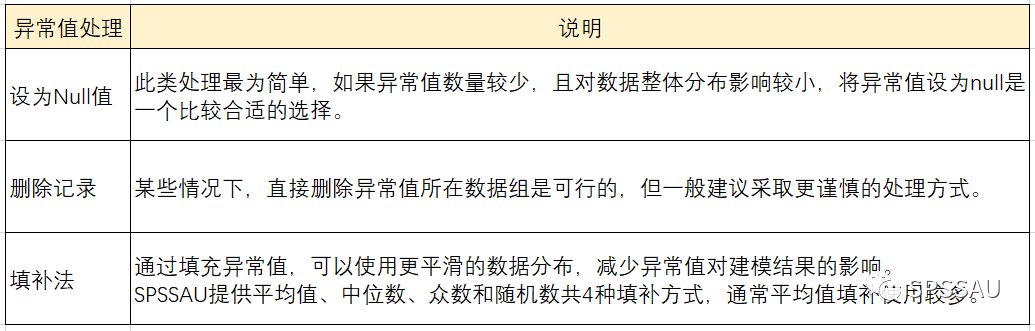
异常值也称离群值,其数值明显偏离它所属样本集的其余观测值。比如身高的数据中,有一人身高为5米,忽视异常值的存在可能会对建模结果产生不良影响。
检测异常值的方法有很多种,常见的比如描述分析法——在3σ原则下,异常值如超过3倍标准差,那么可以将其视为异常值;图示法——比如通过箱线图、散点图进行判断等等。
异常值处理通常有以下3种方式:
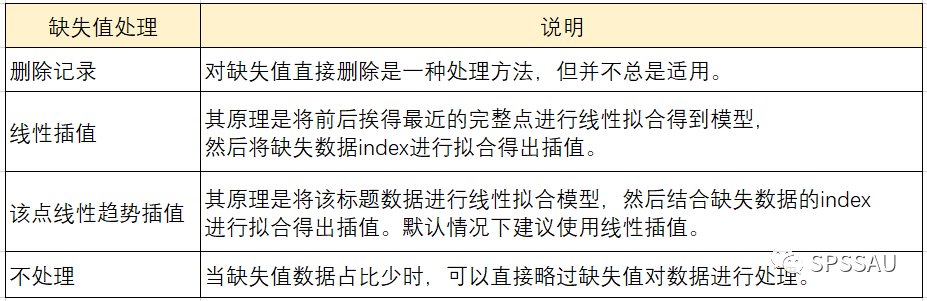
2、缺失值处理
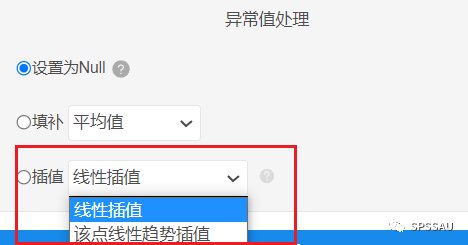
对缺失值进行处理方法通常有删除记录、线性插值、该点线性趋势插值、不处理等4种方法,说明如下表:
在选择数据分析方法时,我们需要考虑方法的可行性和可操作性。一些高级的统计方法可能需要更多的计算资源和时间,因此我们需要结合自己对统计软件的掌握程度选择适合的分析方法,以便更好地完成毕业论文。
如果是统计学小白,那么推荐使用在线数据分析软件SPSSAU进行毕业论文数据分析。只需要点一点就能完成复杂高级的统计方法分析。每种方法都配有相应的帮助手册与教学视频,拿出20分钟即可完成统计方法的学习以及软件的使用。


陶诗和4811SPSS中缺失值填充 -
傅君榕13711199688 ______ 可以采用em法填充 弹出窗口后,把所有变量移入 对话框中 ,然后选择EM法,并点击EM选项进入后,保存新数据,就可以完成填充 并生成新的数据集了
陶诗和4811用spss补全数据 -
傅君榕13711199688 ______ 这里有缺失值插补调整的几种方法可以参考.1、你首先需要定义你数据中的缺失值:SPSS的窗口有两个视窗,数据视窗和变量视窗,你在变量视窗中,可以看到有missing那一列,你可以将某种取值定义为缺失值...
陶诗和4811spss如何用剔除极端值,例如有的人回答的时候全选一个答案,如何利用SPSS将其剔除 -
傅君榕13711199688 ______ SPSS中的缺失值处理有专门的程序,在Analysis菜单下的Missing Data Analysis.可以提供缺失数据的详细信息和填补/删除缺失数据,填补的方法有EM和回归,删除的方法有列删和对删. 对于缺失情况的描述分析中有一个表“Data Pattern(...
陶诗和4811spss 作图时如何去掉 缺失值 ? -
傅君榕13711199688 ______ 在用spss作图时,特别是饼图,如何不显示缺失值. 这个问题除了1楼的做法.还可以直接在图上面单击,那样可以去掉缺失值,还能把一些不要的自变量也去掉,另外还可以更改颜色,字体,是否在图中显示数值或百分值等. 在用二分法录入多选题之后,如何统计,如何和其它题做交叉分析 这个问题,因为多选题只能是0或1,也就是选还是没选.输完后一般可以用描述统计,至于和其它题的交叉分析,可以试试cross带头的 那个命令.
陶诗和4811数据缺失想要补齐有什么方法,用spss的替换缺失值和缺失值分析完全不会用 -
傅君榕13711199688 ______ 1、均值插补.数据的属性分为定距型和非定距型.如果缺失值是定距型的,就以该属性存在值的平均值来插补缺失的值;如果缺失值是非定距型的,就根据统计学中的众数原理,用该属性的众数(即出现频率最高的值)来补齐缺失的值.2、利...
陶诗和4811spss数据输入时,缺失值我用999代替,开始数据分析时,999怎么处理? -
傅君榕13711199688 ______ 分析数据时,不用管它,会自动作为缺失值处理. 当然,可以用插被法等进行缺失值填充,但这种方法存在弊端,所以,一般来说,缺失值可以不用处理. 若有帮助,请及时采纳,谢谢 统计人刘得意
陶诗和4811SPSS中如何在数据视图中补齐missing value? -
傅君榕13711199688 ______ 在变量视图里,每个变量会有很多个属性,其中之一就是”缺失“,默认值为”无“,可以通过设置”缺失“的属性值=9,并在数据视图里将所有的缺失值用9来代替,以补齐缺失数据,又不影响分析结果.
陶诗和4811您好,我想问您一个SPSS的问题. 我要计算2列数据的平均值,但有缺失值存在,我该怎么操作? 谢谢~
傅君榕13711199688 ______ 1、不计算缺失值,把有缺失值的变量删掉 2 在转置中用平均数替代缺失值均可
陶诗和4811在SPSS当中如何实现以下操作:将极大和极小的5%的数值都当作缺失值处理.
傅君榕13711199688 ______ 两步: 1:Transform-Rank cases选入你的收入变量,在Rank type中勾选Fractional rank as %,之后会新输出个收入秩次百分比的变量. 2:之后Recode收入变量为一个新变量,IF条件如果收入秩次小于%5或大于95%的,设置为缺失,就行了. 需要注意的是原收入变量里头的缺失值别忘了设置好.