自我鉴定ai生成
作者|黄楠、李梅
推理能力是机器接近人类智能的一个重要指标。
最近的大型语言模型(Large language mode,LLM)正在变得越来越擅长推理,背后的一个关键技术是思维链(chain-of-thought,CoT),简单来说,CoT 可以让 LLM 模拟人类思考的过程,帮助大型语言模型生成一个推理路径,将复杂的推理问题分解为多个简单的步骤,而不仅仅只是一个最终答案,从而增强模型的推理能力。
对人类而言,我们推断得出一个结论后,往往会通过重新验证来进行核对、避免错误。但当 LLM 在通过 CoT 执行复杂推理尤其是算术和逻辑推理的过程中若出现错误,会在一定程度上影响推理效果,所以不得不进行人工验证。
那么能不能让语言模型也具备自我纠错和自我验证的能力呢?
近日,中国科学院自动化所的研究团队提出了一种新方法证明了 LLM 可对自己的推理结论进行可解释的自我验证,从而大大提高推理性能,这让 LLM 朝着人类智能又前进了一步。

当涉及复杂推理时,语言模型往往缺乏稳健性,一旦发生任何一个小错误,都可能会改变命题的全部含义,从而导致出现错误答案。使用CoT 提示进行推理时,问题会更严重,由于模型没有纠错机制,以至于很难从错误的假设中纠正过来。
以往的一种解决方法是通过训练验证器(verififiers)来评估模型输出正确性。但训练验证器有三个大缺点:需要大量的人力和计算资源、可能存在误报、可解释性差。
为此,中科院团队提出让 LLM 进行自我验证。
首先,假设推理问题中的所有条件对于得出结论都是必要的,给定结论和其他条件后,可推导出其余条件。自我验证分两个阶段进行:
正向推理,LLM 生成候选思维链和结论给定的问题文本;
反向验证,使用 LLM 来验证条件是否满足候选结论,并根据验证分数对候选结论进行排序。
如下图,对于“Jackie 有 10 个苹果(f1),Adam 有 8 个苹果(f2),Jackie 比 Adam 多了多少个苹果?”这个问题,可从 f1 和 f2 推理出结论 fy。然后,通过反向验证来检验该结论的准确性,就像解方程一样,如果以 f2 和 fy 为条件,可以得出 f1,通过验证 f1 是否与原来的 f1 结果一致,可以判断 fy 的正确性。

图 1:正向推理与反向验证
研究表明,LLM 仅需少量提示即可使用自我验证,无需训练或梯度更新。它们用候选结论来验证,解决了原 CoT 中偏离正确思维过程的问题。而且,验证分数源自整个思维推理过程,可解释性很高。
通过对 GPT‑3、CODEX 和 Instruct‑GPT 等大模型的实验分析,这项研究证明了 LLM 具备可解释的自我验证能力。
自我验证的整个过程如图 2所示。第一步与 CoT 类似,但研究通过采样解码生成多个候选结论,计算每个候选结论的验证分数,并选择最高分数作为最终结论。
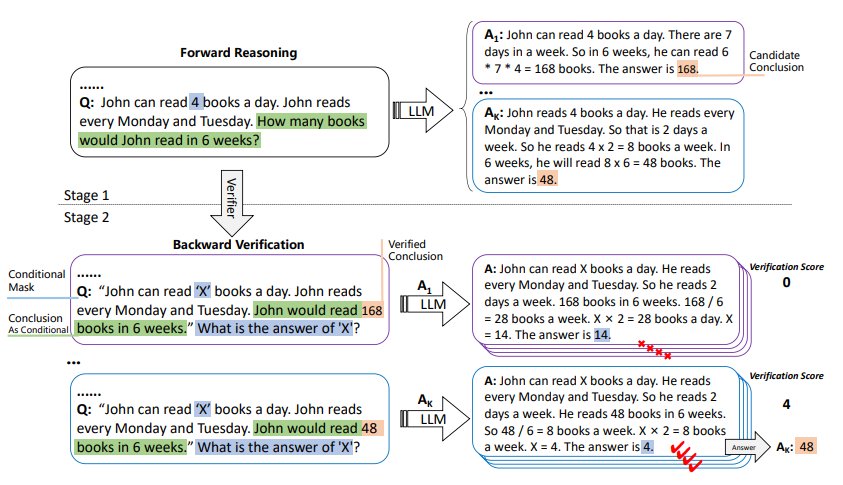
图 2:自我验证示例;LLM 在第一阶段中生成一些候选结论,三个预训练语言模型用于大量自动构建的数值推理问题,但这些方法需要大量的数据和专家注释,然后 LLM 依次验证这些结论,统计推理正确的屏蔽条件的个数作为第二阶段的验证分数

图 3:这是一个需要使用多个条件的示例;如果只屏蔽第一个证据,则不需要这个证据(前向推理时,需要计算周末的钱,周五的工作时数不影响最终结论)。因此,我们无法根据现有条件和任何候选结论来预测此证据
2.1 候选结论生成
给定一个语言模型 M 和一个问答数据集 D,CoT 为 D 设计了一组样本 C,其中包含 n 个样本,epoch 样本有包含条件和问题的输入 X,思维过程 t 和结论 y。这些示例用作测试时间的输入。通常 n 是一位数,因此需要语言模型 M 在生成 y 之前安装 C 生成 t 的提示:
C 中的每个示例都连接为提示。
使用 Sampling 解码生成 K y,K 是 y 的个数。具体来说,采样译码是一种随机译码方法,它可以在每一步从可能生成的词的概率分布中采样来选择下一个词,重复使用 Sampling 解码可以得到多个候选结论。
2.2 条件和结论的重写
对输入的 X 进一步细分为其中每个 f 是一个条件,q 是一个问题。我们使用命令“请把问题和答案改成完整的陈述句[q] The answer is [y]”通过 M 把 q 和 y 改成新的陈述句 fy 。
在问题生成上,问题的多样性使得在实际操作中很难平衡问题和答案之间的连贯性和事实一致性的需要,因此直接屏蔽条件。首先,通过正则匹配找到 f1 中的值改写为 X,在新问题的末尾加入“What is the answer of X?” ,从而提示语言模型指示目标。
2.3 依次验证
如图 4 所示,如果给定的 X 不满足所有条件都是结论的必要条件,可以发现只有掩码的第一个条件会有局限性,难以准确评估其验证分数。为了解决这个问题,可以采用多个条件依次验证的方法:依次用 X 替换原始 X 中出现的所有 f,并要求 M 重新预测它,提高验证的可靠性和准确性。
图 4:在八个基准数据集上进行评估,这些基准数据集涵盖了算术推理、常识推理和逻辑推理任务
2.4 验证分数
研究人员设计了一个类似于正向推理的 CoT 以指导 LLM 生成解决过程。而反向验证过程类似于求解方程式,可将其最终结果与屏蔽条件进行匹配。
由于 LLM 本身性能有限,在反向验证过程中,单次解码会因随机性导致验证结果出现偏差,难以保证更准确的验证分数。为了解决这个问题,采样解码过程将重复 P 次,这样验证分数就可以更准确地反映模型对给定结论的置信度。
验证分数计算如下:
其中,1(.)为指示函数,从生成的 K 个候选答案中选择验证分数最高的一个作为结果,
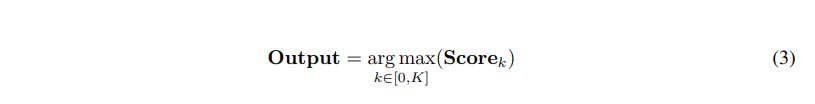
任务和数据集
此项研究评估了6个算术推理数据集,进一步证明了自我验证在常识推理和逻辑推理数据集上的有效性。这些数据集在输入格式方面高度异质:
算术,前两个是一步推理的数据集,后四个需要多步推理,解决起来比较有挑战性
常识,CommonsenseQA(CSQA)需要使用常识和关于世界的知识才能准确回答具有复杂含义的问题,其依赖于先验知识来提供准确的响应
逻辑,日期理解要求模型从一个上下文推断日期
型号
研究人员在实验中测试来原始 CODEX 模型和 Instruct‑GPT 模型,此外还通过使用 GPT‑3 进行分析实验,研究了不同参数级别对可验证性的影响,LLM 的大小范围为 0.3B 到 175B 。这些实验使用了 OpenAI 的 API 来获得推理结果。
实验结果表明,使用了自我验证的两个模型在多个任务中实现了 SOTA 性能。
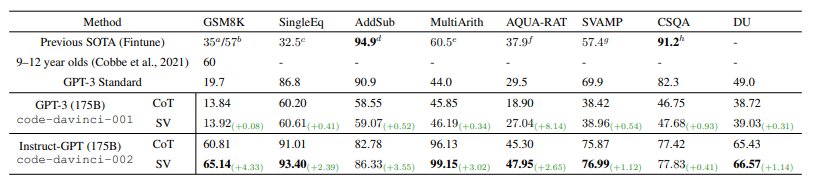
图 5:推理数据集上的问题解决率(%)
可以看到,自我验证在算术数据集上实现了1.67%/2.84%的平均改进,并为常识推理和逻辑推理任务带来了少量优化。此外,自我验证还直接导致高性能 Instruct‑GPT 模型结果平均增加2.33%,这表明,具有强大前向推理能力的模型也具有很高的自我验证能力。
研究人员进一步发现了以下几个关键结论。
可用条件越多,验证准确性越高
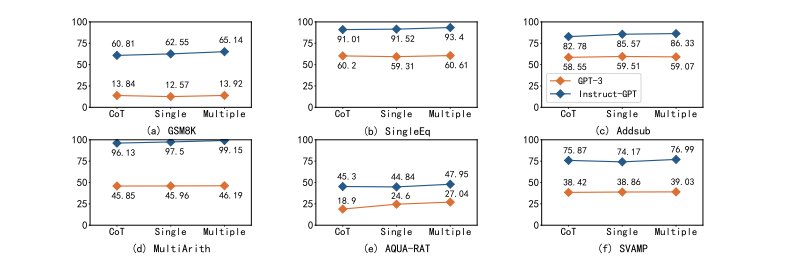
图 6:单条件验证与多条件验证的问题解决率(%)比较
图 6 中观察了对六个不同算术数据集使用单一条件掩码的效果:由于这些数据集输入中的每个数字都可以被视为一个条件,因此可以研究增加验证条件数量的影响。经大多数实验可发现,多条件掩码比单条件掩码表现更好,并且都比原始 CoT 表现更好。
模型越大,自我验证能力越强
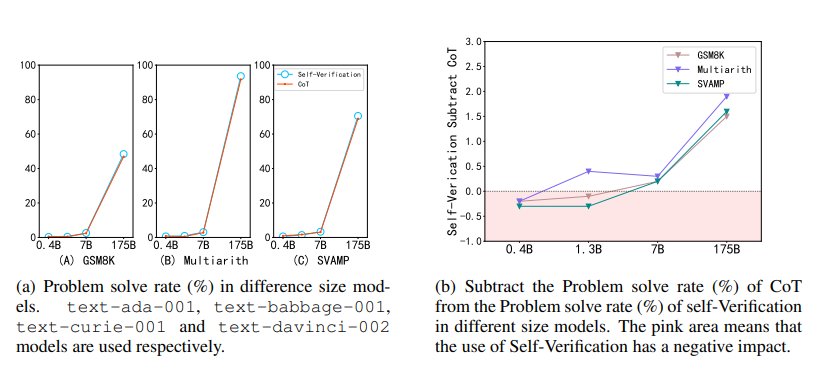
图 7:不同尺寸模型的自我验证能力
图 7显示了参数从 0.4B 到 175B 的 GPT‑3 模型能力。实验结果表明,当参数较小时,模型的自验证能力较弱,甚至不如 CoT 的原始性能。这说明,模型的自我验证也是一种涌现能力,且往往出现在更大的模型中。
思维链提示很少并不影响自我验证能力
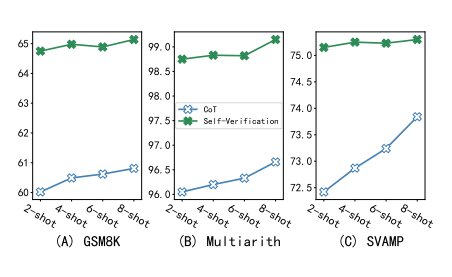
图 8:2 次提示和8 次提示的问题解决率(%)比较
图 8 所示的实验结果显示了不同的提示量对性能的影响。可以看到,自我验证在较小的样本中表现出更大的稳健性,甚至低至 2 次,这时候其 8 次提示的性能是 99.6%,而 CoT 只有 98.7%。不仅如此,即使只有 4 个提示(2 个 CoT 提示+ 2 个自我验证提示),自我验证也明显优于 CoT 8 次提示,突出了自我验证在数据有限情况下的重要性。

图 9:不同验证方式的提示对比
与其它方法相比,条件掩码的自我验证性能更优
有另一种方法可以验证模型答案的正确性:真-假项目验证,这以方法是模型对所有条件进行二分判断,如图 12 所示,不覆盖任何条件。此研究还提供了一个反向推理的例子,并尝试让模型自动从结论是否满足条件进行反向推理,但实验结果如图 10 所示,真-假项目验证的性能,要落后于条件掩码验证的性能。
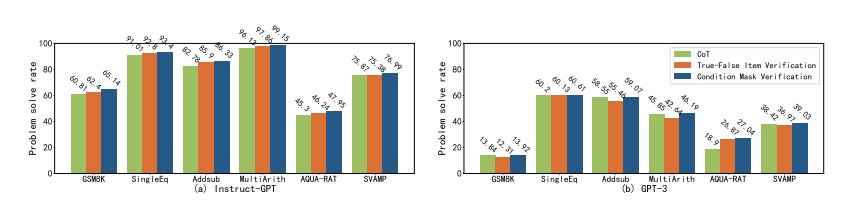
图 10:6 个算术数据集的问题解决率(%)条件掩码验证和真-假项目验证的比较
为了理解这种差距的原因,研究分析了具体案例,如图 11 所示,结果表明:(1)缺乏明确的反向推理目标导致模型再次从正向推理,该结果没有意义、并且不利用现有的结论;(2)真-假项目验证提供了所有的条件,但这些条件可能会误导模型的推理过程,使模型没有起点。因此,更有效的做法是使用条件掩码验证,从而更好地激发模型的自我验证能力。

图 11:一些实际生成案例进一步展示了不同验证方法的影响
LLM 的自我验证能纠错,但可也能「误伤」
图 12 展示了 LLM 使用自我验证来验证其自身结果的详细结果:
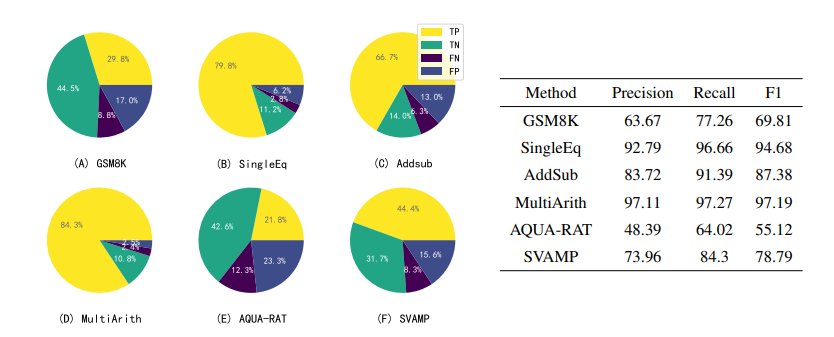
图 12:使用 Instruct‑GPT 为八个数据集中的每一个生成了五组候选答案,然后利用 Instruct‑GPT 的自我验证 能力,对它们进行一一判断和排序
左边的扇形图显示了自我验证产生的候选结论的预测结果。LLM 在每次提示中产生1-5个候选结论(由于 LLM 的自洽性,可能会产生相同的候选结论),这些结论可能是正确的,也可能是错误的,再通过 LLM 自我验证来检验这些结论,并将其类为真阳性(TP)、真阴性(TN)、假阴性(FN)或假阳性(FP)。可以发现,除了 TP 和 TN 之外,还有大量的 FN,但只有少量的 FP。
右边的表格显示了召回率明显高于准确率,由此可以说明,LLM 的自我验证可以准确剔除不正确的结论,但也可能将一个正确结论错误地认为是不正确的。这可能是由于反向验证时方程错误或计算错误造成的,这一问题将在未来解决。
最后总结一下,这项工作提出的自我验证方法能够让大型语言模型和提示来引导模型验证自己的结果,能提高 LLM 在推理任务中的准确性和可靠性。
但需要注意的是,这些提示是人为构造的,可能会引入偏差。所以方法的有效性会受到 LLM 产生的候选结论中正确答案的存在的限制,因此取决于模型正确前向推理的能力。
此外,该方法涉及生成多个候选 CoT 和结论,这对于 LLM 来说也存在计算资源的消耗。虽然它可以帮助 LLM 避免来自不正确的 CoT 干扰,但也可能无法完全消除推理过程中的错误。
更多内容,点击下方关注:

未经「AI科技评论」授权,严禁以任何方式在网页、论坛、社区进行转载!
公众号转载请先在「AI科技评论」后台留言取得授权,转载时需标注来源并插入本公众号名片。
未经「AI科技评论」授权,严禁以任何方式在网页、论坛、社区进行转载!
公众号转载请先在「AI科技评论」后台留言取得授权,转载时需标注来源并插入本公众号名片。
雷峰网
","force_purephv":"0","gnid":"96abbbab0295d44d9","img_data":[{"flag":2,"img":[{"desc":"","height":"489","title":"","url":"https://p0.ssl.img.360kuai.com/t0139fa894b43b6d1e5.jpg","width":"1080"},{"desc":"","height":"268","title":"","url":"https://p0.ssl.img.360kuai.com/t01a713ee4567d101f7.jpg","width":"1080"},{"desc":"","height":"485","title":"","url":"https://p0.ssl.img.360kuai.com/t01e2c77998e1daff7d.jpg","width":"843"},{"desc":"","height":"335","title":"","url":"https://p0.ssl.img.360kuai.com/t01ea5df687c4439e25.jpg","width":"801"},{"desc":"","height":"228","title":"","url":"https://p0.ssl.img.360kuai.com/t015a56d7a4e8df03b9.jpg","width":"841"},{"desc":"","height":"104","title":"","url":"https://p0.ssl.img.360kuai.com/t014b0cf121b4fbaad7.jpg","width":"815"},{"desc":"","height":"187","title":"","url":"https://p0.ssl.img.360kuai.com/t0113af77c3264c0457.jpg","width":"816"},{"desc":"","height":"263","title":"","url":"https://p0.ssl.img.360kuai.com/t0196cc533f688daca7.jpg","width":"799"},{"desc":"","height":"371","title":"","url":"https://p0.ssl.img.360kuai.com/t017b5f203fe79adb8a.jpg","width":"821"},{"desc":"","height":"277","title":"","url":"https://p0.ssl.img.360kuai.com/t011c9bafddd79e9b5b.jpg","width":"452"},{"desc":"","height":"159","title":"","url":"https://p0.ssl.img.360kuai.com/t01fab9a5325fe2c538.jpg","width":"847"},{"desc":"","height":"221","title":"","url":"https://p0.ssl.img.360kuai.com/t0133e97907467770ca.jpg","width":"853"},{"desc":"","height":"515","title":"","url":"https://p0.ssl.img.360kuai.com/t01a679db72260cae52.jpg","width":"841"},{"desc":"","height":"337","title":"","url":"https://p0.ssl.img.360kuai.com/t01f657e4fc040dc156.jpg","width":"834"},{"desc":"","height":"300","title":"","url":"https://p0.ssl.img.360kuai.com/t01720106cf95731d77.jpg","width":"700"}]}],"original":0,"pat":"zzc,art_src_1,sexf,sex4,sexc,fts0,sts0","powerby":"hbase","pub_time":1671792924000,"pure":"","rawurl":"http://zm.news.so.com/ba5f0116d0557f80f77b26619723fa07","redirect":0,"rptid":"5bdc4f4274c1faa7","s":"t","src":"雷峰网","tag":[{"clk":"kscience_1:f1","k":"f1","u":""}],"title":"中科院 AI 团队最新研究发现,大模型可通过自我验证提高推理性能
甘瑗南2732简历自我评价怎么写? -
邰邓耐19195253739 ______ 写一份动人的简历也是找工作中最难的一部分,但是,通过下面步骤,这件事不再那么难了. 选择目标 先决定你要怎么样的工作,然后写在一张白纸上.这个目标没必要一定要出现在你的简历上.有时候,写在自荐信上会更好.如果你知道你...
甘瑗南27322021年大学学生自我鉴定
邰邓耐19195253739 ______ 自我鉴定是个人在一个时期对自己的学习或工作生活的自我总结,它能够给人努力工作的动力,为此要我们做好自我鉴定.如何把自我鉴定做到重点突出呢?以下就是小编...
甘瑗南27322022大学毕业生自我鉴定5篇
邰邓耐19195253739 ______ 鉴定是个人在一个时期对自己的学习或工作生活的自我总结,自我鉴定可以总结以往思想,发扬成绩,不如我们来制定一份自我鉴定吧.下面是小编精心推荐的大学毕业生...
甘瑗南27322022实习自我鉴定600字
邰邓耐19195253739 ______ 实习是每个大学生必须面对和经历的过程,实习生自我鉴定即实习人员对自己在实习期间的工作表现作出自我评价.下面是小编给大家整理的2022实习自我鉴定600字(精...
甘瑗南2732企业安全生产情况自我鉴定怎么写 -
邰邓耐19195253739 ______ 企业安全生产情况自我鉴定: 以教育为本,文修武练,提高全员安全意识和战斗力.在安全生产及其活动的实践过程中,我们体会到除领导重视负责是必不可少外,以下两个方面是安全生产的重中之重. 1、安全知识、认识和观念.安全生产事...
甘瑗南2732大二学生德智体自我鉴定
邰邓耐19195253739 ______ 为自己的工作做总结或是自我鉴定,需要以客观的角度,深度挖掘自己的不足和优势,这将对以后的工作有莫大的好处.下面是小编为大家整理的关于大二学生德智体自我...
甘瑗南2732机电一体化毕业自我鉴定 谢谢 -
邰邓耐19195253739 ______ 经过大学四年机电一体化专业课程的学习,谦虚自律的我,乐观向上、为人真诚、坦率,能吃苦耐劳具有团队合作精神,有较强的适应能力和自学能力,不易受外界环境的干扰,在学习上,我成绩良好,多次获得奖学金,通过课余时间学习参加...
甘瑗南2732最新2022年优秀大学生实习自我鉴定范文
邰邓耐19195253739 ______ 大学生通过实习可以更进一步的接近自己向往的公司单位,为以后的就业做好铺垫和提供参考.小编在这给大家带来最新2022年优秀大学生实习自我鉴定范文5篇,欢迎大...