随机变量观测值是什么

传统的观察性研究中,潜在混杂和反向因果关系会影响其因果推断能力。孟德尔随机化( Mendelian randomization, MR)是工具变量(instrumental variable, IV)分析的一种类型,它使用遗传变异作为IV来检测和量化因果关系。
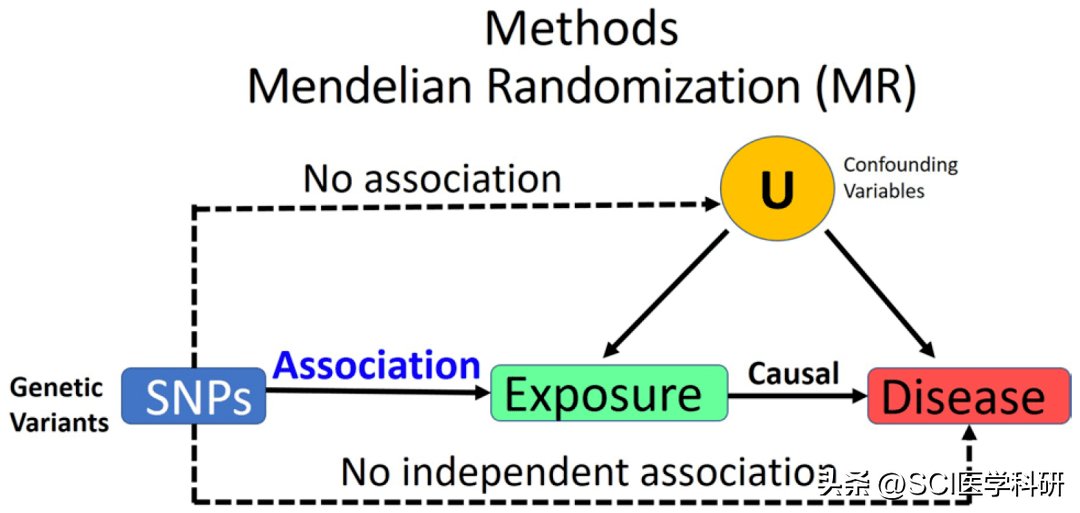
由于能克服潜在混杂和反向因果关系的影响,近年来MR在观察性研究中的应用越来越广泛。早期的MR研究通常在小样本人群中进行,且仅使用了少量的遗传变异问,这使得MR研究的效力较低。然而,随着生物学界发现了大量与特定性状紧密相关的遗传变异,加上许多大样本全基因组关联( genome-wide association study, GWAS)公开发布了数十万个暴露和疾病与遗传变异关系的汇总数据,这一领域发生了一场革命。

这些汇总数据使得研究者能估计大样本数据中的遗传关联,从而促进了MR研究发展。近年来,该领域在方法学上也迅速更新,新方法克服了传统MR方法的一些特定限制,但其同样存在局限性。只有正确了解MR背后的原理、局限性及不同方法的适用条件才能针对不同的研究问题和特定的数据正确应用MR。
基因遗传学的快速发展,促使孟德尔随机化(Mendelian randomization, MR)在医学研究和实践中的兴起与发展"。MR一词最早出现在1991的一个骨髓移植治疗儿童恶性肿瘤的研究中,通过基因匹配检测发现有人类白细胞抗原匹配患儿的骨髓移植接受度优于无匹配患儿叫。可见,通过检测特定关联基因的分布可预测治疗效果(或暴露结局)。MR利用基因型工具变量,基于工具变量与暴露因素强关联、工具变量与混杂因素无关联及工具变量仅通过暴露与结局关联的三大假设,来推断暴露与结局的关系"。因MR可规避剩余混杂因素对关联结果准确性的影响,使得关联结果论证强度比观察性研究甚至随机对照试验还可靠。2021年,Xu等对Web of Science数据中收录的MR研究分析后发现近年发文数量正快速增长,表明MR研究已成为流行病学的研究热点。

姜鬼重2425随机变量是什么?他可以取负值吗? -
潘储于18286732020 ______ 随机变量:指在一定范围内以一定的概率分布随机取值的变量.可以取负值.
姜鬼重2425随机变量的观测值越大,说明两个分类变量之间没有关系的可能性( ) -
潘储于18286732020 ______[选项] A. 越大 B. 越小 C. 不变 D. 无法确定
姜鬼重2425利用随机变量K2来判断“两个分类变量X,Y有关系”时,K2的观测值k的计算公式为:k= n(ad−bc)2 (a+b)(c+d)(a+c)(b+d),则下列说法正确的是( ) -
潘储于18286732020 ______[选项] A. ad-bc越小,说明X与Y关系越弱 B. ad-bc越大,说明X与Y关系越强 C. (ad-bc)2越大,说明X与Y关系越强 D. (ad-bc)2越接近于0,说明X与Y关系越强
姜鬼重2425离散程度计算公式
潘储于18286732020 ______ 离散程度计算公式:η=G/(G+G动).离散程度,英文名MeasuresofDispersion,是指通过随机地观测变量各个取值之间的差异程度,用来衡量风险大小的指标.随机变量(randomvariable)表示随机试验各种结果的实值单值函数.随机事件不论与数量是否直接有关,都可以数量化,即都能用数量化的方式表达.
姜鬼重2425进行一元线性回归分析时,总是假定?a.自变量是随机变量,因变量是非随机变量b.两变量都是随机变量c.自变量是非随机变量,因变量是随机变量d.两变量都... -
潘储于18286732020 ______[答案] c x是观测值,一旦观测就确定了,y是随机变量,因为有测量误差的出现,是随机的
姜鬼重2425什么叫随机变量? -
潘储于18286732020 ______ 随机变量 random variable 表示随机现象各种结果的变量.例如某一时间内公共汽车站等车乘客的人数,电话交换台在一定时间内收到的呼叫次数,等等,都是随机变量的实例.一个随机试验的可能结果(称为基本事件)的全体组成一个基本空...
姜鬼重2425下列说法中正确的是( )A.若分类变量X和Y的随机变量K2的观测值k越大,则“X与Y相关”的可信程度越小 -
潘储于18286732020 ______ A.若分类变量X和Y的随机变量K2的观测值k越大,则“X与Y相关”的可信程度越大,∴A错误. B.对于自变量x和因变量y,当x取值一定时,y的取值具有一定的随机性,x,y间的这种非确定关系叫做相关关系,∴B错误. C.相关系数r2越接近1,表明两个随机变量线性相关性越强,∴C错误. D.若分类变量X与Y的随机变量K2的观测值k越小,则两个分类变量有关系的把握性越小,∴D正确. 故选:D.
姜鬼重2425对模型参数估计的方法有多种,对于满足基本假定的线性回归模型的估计,最简 -
潘储于18286732020 ______ 1、随机误差项是一个期望值或平均值为0的随机变量; 2、对于解释变量的所有观测值,随机误差项有相同的方差; 3、随机误差项彼此不相关; 4、解释变量是确定性变量,不是随机变量,与随机误差项彼此之间相互独立; 5、解释变量之间不存在精确的(完全的)线性关系,即解释变量的样本观测值矩阵是满秩矩阵; 6、随机误差项服从正态分布.
姜鬼重2425如何构造变换,使得无偏且不依赖于随机变量 -
潘储于18286732020 ______ 1、随机误差项是一个期望值或平均值为0的随机变量; 2、对于解释变量的所有观测值,随机误差项有相同的方差; 3、随机误差项彼此不相关; 4、解释变量是确定性变量,不是随机变量,与随机误差项彼此之间相互独立; 5、解释变量之间不存在精确的(完全的)线性关系,即解释变量的样本观测值矩阵是满秩矩阵; 6、随机误差项服从正态分布.
姜鬼重2425如果随机变量K2的观测值k≈8.254,这就意味着“分类变量X与Y有关系”这一结论成立的可能性为___. -
潘储于18286732020 ______[答案] K2>k)0.500.400.250.150.100.050.0250.0100.0050.001k0.4550.7081.3232.0722.7063.8415.0246.6357.87910.828根据随机变量K2的观测值对应表知,当k≈8.254>7.879时, 而7.879对应的出错率是0.005, 所以意味着分类变量X,Y有关系的可能性为...