hadoop核心组件
在金融行业,大数据分析被应用于个人及企业客户画像、精准营销、欺诈识别、风险评估、风险管理与控制、交易分析、运营优化、智能投资等领域。
金融业务的特点使得业务应用对计算和存储的能力要求较高。为了高效、安全、完整地完成存储和计算的建设任务,应该用“存算一体”还是“存算分离”架构?

问:在金融行业,为什么“大数据存算分离“才是未来?
随着大数据系统建设的深入,企业的数据基础设施易出现计算资源浪费、存储性能低、管理成本过高等挑战。相比存算一体架构,存算分离架构具有性能与成本最优、兼具灵活性等特点,因此受到企业IT部门的青睐。
“存算一体”难以满足大数据分析发展的需求
Hadoop是金融行业常用的大数据系统解决方案,以解决海量数据存储及分析计算的问题。HDFS是Hadoop的核心组件,提供了高可靠、高吞吐的分布式文件系统。其存储与计算高度融合形成存算一体架构。
随着金融业务规模逐步扩大,每天产生如客户信息、交易记录、市场行情、风险指标、系统日志等海量的数据,数据规模成指数级爆发增长。在存算一体架构中计算与存储是强绑定关系,不可避免地会同时争夺服务器有限的CPU等公共资源。金融行业分析业务相对集中,在业务繁忙时容易出现瓶颈,性能低下。存算一体架构逐渐难以适应和支撑金融业大数据分析发展的要求,主要体现在以下几点:
1.灵活性差。金融业务繁多,大数据分析任务对资源的需求难以被提前精确规划。而存算一体架构通常需要在计算和存储资源之间进行平衡,以满足不同任务的需求。这种平衡可能会大大限制系统的灵活性,使得在面对不同类型和规模的任务时,难以进行有效的资源管理和调度。
2.资源利用率低。在存算一体架构中,计算和存储资源是共享的,但金融业不同分析任务对计算和存储的需求不同。执行存储密集型任务或计算密集型任务时,服务器资源可能没有被充分调度使用或出现任务间相互影响制约,从而导致资源利用率低下。
3.无法按需扩展。金融业的历史数据需要长期保存并随时被调用,可能需要同时对每周、每月、每年的数据执行批量分析任务。随着数据量的增长,数据存储的容量要求不断增长。而计算资源的需求往往跟不上存储容量的要求。由于存算一体架构的计算和存储紧密耦合,存储资源的扩展伴随着计算资源同时扩展,从而导致成本和复杂性的增加。
“存算一体”转向“存算分离”成为大势所趋
随着近年来大数据应用的广泛普及,传统的存算一体模式弊端逐步凸显。从业务需求和大数据技术发展趋势看,大数据计算、存储分离已势在必行。
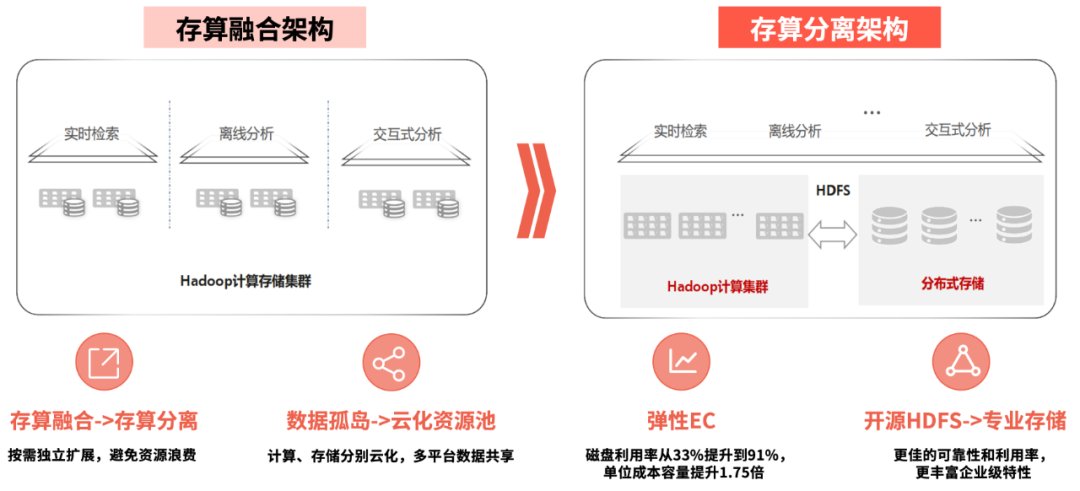
从当前存算分离业务实践来看,主要包括以下几个方面的核心价值:
1.灵活扩展。存算分离架构允许独立地扩展存储和计算资源,可以根据实际需求动态地调整资源配置,从而提高系统的灵活性和可扩展性。存算分离架构可以支持横向扩展和纵向扩展,根据业务需求灵活调整计算和存储资源的规模;可以利用软件定义存储产品提供的HDFS兼容接口能力,无缝对接原有Hadoop系统,实现平滑升级,并带来丰富的企业级特性,从而更好地适应金融业市场变化和业务增长。
2.优化性能。由于存储和计算资源可以独立地进行优化和升级,存算分离架构可以更好地适应不同的计算负载和存储需求。对访问频繁的数据,可以采用专业的软件定义存储通过本地化缓存等高级特性,降低数据访问的延迟和网络带宽的需求,从而提高系统的性能。
3.提高资源利用率。存算分离架构可以更好地利用存储和计算资源,减少资源的浪费和重复利用;利用云化共享资源池,摆脱数据孤岛,资源在不同的业务间共享,提高资源利用率。
4.提升数据可靠性。存算分离后,可以利用专业的企业级存储引入丰富的数据保护特性,如多故障域、亚健康检测、快速重构、故障自愈机制等特性提升可靠性。
5.降低存储成本。存算分离架构可以将计算和存储资源独立扩展,从而降低硬件和运维成本。对金融业历史数据,由于其访问频繁度降低,可以利用专业软件定义存储产品的EC特性等,满足业务性能要求的同时提高得盘率,从而降低存储成本。
","gnid":"9dbb3c46ec461e58d","img_data":[{"flag":2,"img":[{"desc":"","height":"460","title":"","url":"https://p0.ssl.img.360kuai.com/t01e49c81bf41927276.jpg","width":"1080"},{"desc":"","height":"491","title":"","url":"https://p0.ssl.img.360kuai.com/t016f744082a1092535.jpg","width":"1080"}]}],"original":0,"pat":"art_src_3,fts0,sts0","powerby":"pika","pub_time":1703476380000,"pure":"","rawurl":"http://zm.news.so.com/7df47cc080a47c5c40ac4e7fccf67152","redirect":0,"rptid":"f7f45cabe5844ec5","rss_ext":[],"s":"t","src":"杉岩数据","tag":[{"clk":"ktechnology_1:大数据","k":"大数据","u":""}],"title":"在金融行业,为什么“大数据存算分离”才是未来?
逄平发5205什么是 Hadoop 生态系统 -
池股乐17053735047 ______ Hadoop是一个能够对大量数据进行分布式处理的软件框架.具有可靠、高效、可伸缩的特点. Hadoop的核心是HDFS和Mapreduce,hadoop2.0还包括YARN. 下图为hadoop的生态系统:
逄平发5205MapReduce和Hadoop的理解 -
池股乐17053735047 ______ hadoop是一种分布式系统的平台,通过它可以很轻松的搭建一个高效、高质量的分布系统,而且它还有许多其它的相关子项目,也就是对它的功能的极大扩充,包括Zookeeper,Hive,Hbase等.MapReduce是hadoop的核心组件之一,hadoop要分布式包括两部分,一是分布式文件系统hdfs,一部是分布式计算框mapreduce,也就是说,可以通过mapreduce很容易在hadoop平台上进行分布式的计算编程.
逄平发5205大数据的Hadoop是做什么的? -
池股乐17053735047 ______ 提供海量数据存储zd和计算的.需要java语言基础.Hadoop实现了一个分布zd式文件系统(Hadoop Distributed File System),简称HDFS.有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供专高吞吐量来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序.Hadoop的框架最核心的设计就是:HDFS和MapReduce.HDFS为海量的数据提供了存储,而MapReduce则为海量的数据提供了计算属回.
逄平发5205下列不属于Hadoop生态系统的是 - 上学吧找答案 - 上学吧普法考试
池股乐17053735047 ______ Impala比Spark性能还要好,但你看它现在这个鸟样.认真来讲,Hadoop现在分三块HDFS/MR/YARN,Spark比Hadoop性能好,只是Spark作为一个计算引擎,比MR的性能要好.但它的存储和调度框架还是依赖于HDFS/YARN,Spark也有自己的...