python索引是什么
作者:大橡皮啊
最终效果:
删除重复文件,并保留创建日期更为久远的文件
上篇文章写了,利用群晖的存储空间分析器结合python来查找重复文件.经人提醒,发现完全不需要用到存储分析器.因为那个文章编辑次数到限制了.无法编辑了.只能重新开贴. 有一点小小的设置.看下图
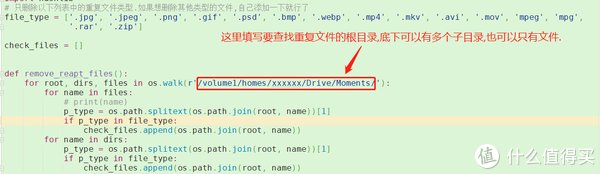
file_type是一个文件类型的列表.在里面添加你想要删除的文件类型即可.每个文件类型之间用逗号隔开.
import os
import hashlib
# 只删除以下列表中的重复文件类型.如果想删除其他类型的文件,自己添加一下就行了
file_type = ['.jpg', '.jpeg', '.png', '.gif', '.psd', '.bmp', '.webp', '.mp4', '.mkv', '.avi', '.mov', 'mpeg', 'mpg',
'.rar', '.zip']
check_files = []
def remove_reapt_files():
for root, dirs, files in os.walk(r'/volume1/homes/xxxxxx/Drive/Moments/'):
for name in files:
# print(name)
p_type = os.path.splitext(os.path.join(root, name))[1]
if p_type in file_type:
check_files.append(os.path.join(root, name))
for name in dirs:
p_type = os.path.splitext(os.path.join(root, name))[1]
if p_type in file_type:
check_files.append(os.path.join(root, name))
files_dict = {}
r_index = 0
print('Fiels Num:%s' % len(check_files))
for value in check_files:
md5_hash = hashlib.md5()
try:
with open(value, "rb+") as f:
for byte_block in iter(lambda: f.read(4096), b""):
md5_hash.update(byte_block)
file_md5 = md5_hash.hexdigest()
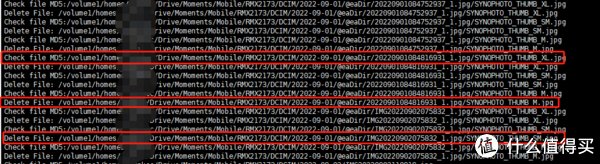
print('Check file MD5:%s' % value)
if files_dict.get(file_md5) is None:
files_dict[file_md5] = value
else:
d_path = files_dict[file_md5]
d_path_stats = os.stat(d_path)
file_stats = os.stat(value)
d_time = d_path_stats.st_ctime
f_time = file_stats.st_ctime
if d_time > f_time:
os.remove(d_path)
files_dict[file_md5] = value
print('Delete File:', d_path)
r_index += 1
else:
os.remove(value)
print('Delete File:', value)
r_index += 1
except Exception as e:
pass
#print('File does not exist or has been deleted')
print('File Count:%s, Repeat Files Num:%s. All deleted!' %( len(check_files),str(r_index)))
if __name__ == '__main__':
remove_reapt_files()
文件下载之后,要添加到计划任务中.
先打开群晖上的File Station 新建一个文件夹.我这边取名叫 python_shell.然后把脚本文件复制到文件夹下.
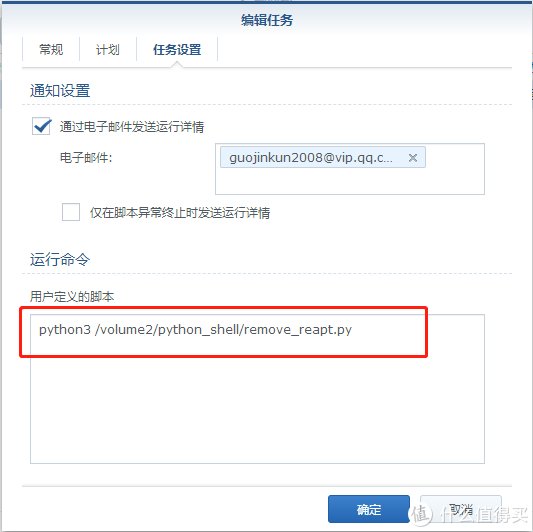
然后打开计划任务,添加一个计划任务.执行频率.看个人喜好.运行命令就写python3 加上脚本的路径
这样就大功告成了.看看效果吧.
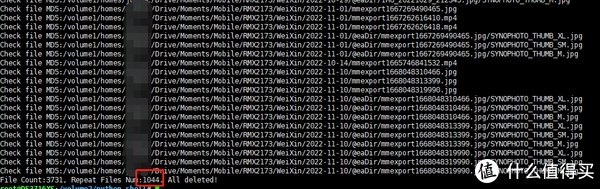
@eadir文件夹是群晖全局索引文件.所以删除的文件要比实际的重复要多.因为索引也删除了.
闻俊会1867请问python中val[0: - 1]是什么意思? -
却刻刷18385993081 ______ val[0:-1]是python特有的切片操作,也叫切割操作,这里的下标0表示左起第一个元素, -1表示倒数最后一个元素. 取一个list或tuple的部分元素是非常常见的操作.比如,一个list如下: “L = ['Michael', 'Sarah', 'Tracy', 'Bob', 'Jack']” 取前3个元素...
闻俊会1867python怎么获取列表元素的索引 -
却刻刷18385993081 ______ #用enumerate函数,最好不要用index ,因为列表有相同的元素的时候,index就傻冒了 for i,j in enumerate(('a','b','c')): print i,j0 a1 b2 c
闻俊会1867python索引 -
却刻刷18385993081 ______ ("a",)代表是一个tuple.("a")代表一个字符串.这个地方也是一个坑,有时候想初始化一个只有一个元素的元组,很容易就写成了("a"),然后就有问题了.可以使用下面的代码查看下: y = ("a", ) z = ("a") print type(y) print type(z)
闻俊会1867什么是索引? -
却刻刷18385993081 ______ 主索引: 通常是唯一的,用于搜索目录的唯一标识. 索引 使用索引可快速访问数据库表中的特定信息.索引是对数据库表中一列或多列的值进行排序的一种结构,例如 employee 表的姓(lname)列.如果要按姓查找特定职员,与必须搜索表中...
闻俊会1867索引是什么 -
却刻刷18385993081 ______ 索引,[1]使用索引可快速访问数据库表中的特定信息.索引是对数据库表中一列或多列的值进行排序的一种结构,例如 employee 表的姓名(name)列.如果要按姓查找特定职员,与必须搜索表中的所有行相比,索引会帮助您更快地...
闻俊会1867计算机索引为什么从0开始 -
却刻刷18385993081 ______ python的创始人(Guido van Rossum)说过,Python使用0-based索引方式的原因之一是Python的切片(slice)语法. 先看看切片的用法.可能最常见的用法就是“从数组中切出前n位”或“从数值这第i位起切出n位”(前一种实际上是i==起...
闻俊会1867list index out of range是怎么回事 -
却刻刷18385993081 ______ 在python中,list index out of range意思是列表的索引分配超出列范围. 对于有序序列: 字符串 str 、列表 list 、元组 tuple进行按索引取值的时候,默认范围为 0 ~ len(有序序列)-1,计数从0开始,而不是从1开始,最后一位索引则为总长度减...
闻俊会1867Python中[:: - 1]这个代码是什么意思? -
却刻刷18385993081 ______ 个人理解是最后一项向后步进时用到的,::1是向后步进1时用到的.删除和插入列表时候,把k位置元素删除并把列表k位置向后步进一位接受数据返回列表原位置,列表长度减一.::-1其实是同理,把元素插入k位置需要将k位置本来的元素向...