python输出出现次数
作者:大橡皮啊
最终效果:
删除重复文件,并保留创建日期更为久远的文件
上篇文章写了,利用群晖的存储空间分析器结合python来查找重复文件.经人提醒,发现完全不需要用到存储分析器.因为那个文章编辑次数到限制了.无法编辑了.只能重新开贴. 有一点小小的设置.看下图
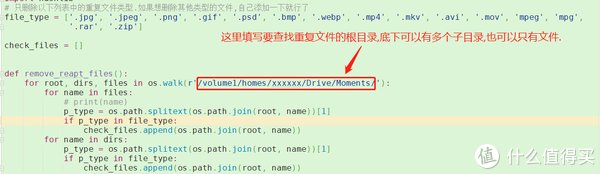
file_type是一个文件类型的列表.在里面添加你想要删除的文件类型即可.每个文件类型之间用逗号隔开.
import os
import hashlib
# 只删除以下列表中的重复文件类型.如果想删除其他类型的文件,自己添加一下就行了
file_type = ['.jpg', '.jpeg', '.png', '.gif', '.psd', '.bmp', '.webp', '.mp4', '.mkv', '.avi', '.mov', 'mpeg', 'mpg',
'.rar', '.zip']
check_files = []
def remove_reapt_files():
for root, dirs, files in os.walk(r'/volume1/homes/xxxxxx/Drive/Moments/'):
for name in files:
# print(name)
p_type = os.path.splitext(os.path.join(root, name))[1]
if p_type in file_type:
check_files.append(os.path.join(root, name))
for name in dirs:
p_type = os.path.splitext(os.path.join(root, name))[1]
if p_type in file_type:
check_files.append(os.path.join(root, name))
files_dict = {}
r_index = 0
print('Fiels Num:%s' % len(check_files))
for value in check_files:
md5_hash = hashlib.md5()
try:
with open(value, "rb+") as f:
for byte_block in iter(lambda: f.read(4096), b""):
md5_hash.update(byte_block)
file_md5 = md5_hash.hexdigest()
print('Check file MD5:%s' % value)
if files_dict.get(file_md5) is None:
files_dict[file_md5] = value
else:
d_path = files_dict[file_md5]
d_path_stats = os.stat(d_path)
file_stats = os.stat(value)
d_time = d_path_stats.st_ctime
f_time = file_stats.st_ctime
if d_time > f_time:
os.remove(d_path)
files_dict[file_md5] = value
print('Delete File:', d_path)
r_index += 1
else:
os.remove(value)
print('Delete File:', value)
r_index += 1
except Exception as e:
pass
#print('File does not exist or has been deleted')
print('File Count:%s, Repeat Files Num:%s. All deleted!' %( len(check_files),str(r_index)))
if __name__ == '__main__':
remove_reapt_files()
文件下载之后,要添加到计划任务中.
先打开群晖上的File Station 新建一个文件夹.我这边取名叫 python_shell.然后把脚本文件复制到文件夹下.
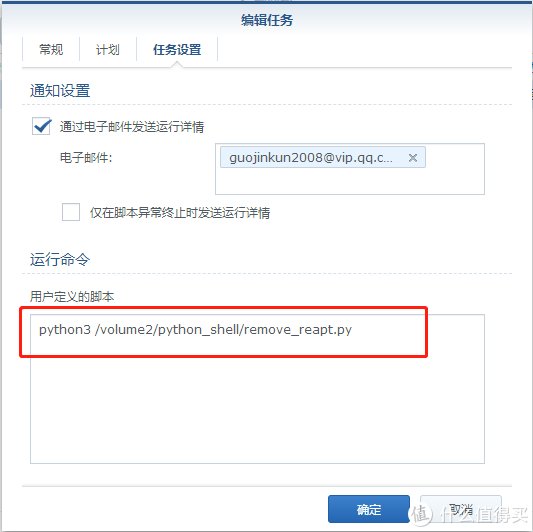
然后打开计划任务,添加一个计划任务.执行频率.看个人喜好.运行命令就写python3 加上脚本的路径
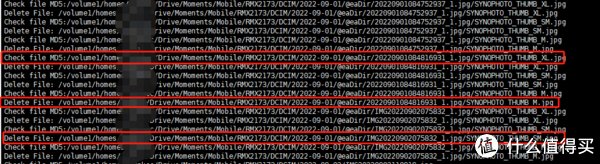
这样就大功告成了.看看效果吧.
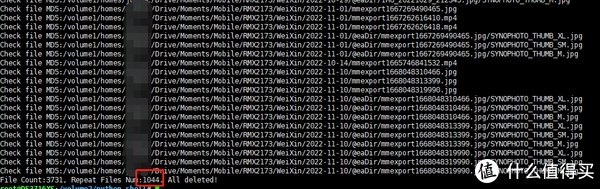
@eadir文件夹是群晖全局索引文件.所以删除的文件要比实际的重复要多.因为索引也删除了.
金易龙5087python计算属性出现的频数 -
沈世尤18895924197 ______ 参考代码:#coding: UTF-8 my_data = [ [1,1],[1,2],[1,3],[1,4],[2,1],[2,2],[2,3],[2,4],[3,1],[3,2],[3,3],[3,4],[4,1],[4,2],[4,3],[4,4] ]# print my_data my_dic = {} for (row_1, row_2) in my_data: my_dic.setdefault(row_1, []) my_dic[row_1].append(row_2) for i in my...
金易龙5087如何用Python编程输入英文语句,将所有字母变成大写,统计每个字母的个数,并输出出现次数最多的字母次数? -
沈世尤18895924197 ______ 下面来是对源应百的度code inputStr ="XXXdsfdssd" aa = inputStr.upper() dict ={} for each in range(len(aa)): if aa[each] in dict: dict[aa[each]] +=1 else: dict[aa[each]] =1 aar = sorted(dict.items(), key=lambda item:item[1]) print (aar[-1])
金易龙5087python 怎么提取列表中出现次数最多的值 -
沈世尤18895924197 ______ import re a = [列表] c = [] for x in a: c.append(re.findall(r'\d+',x))
金易龙5087python写函数返回字频表出现出现次数最多的字及频次 -
沈世尤18895924197 ______ 12345678910111213141516 defrate(): s="aaabbcccdd" count=len(s) d={} fori ins: d[i]=d.get(i,int(0))+1 #print(d) cnt=-1 for(K,V) insorted(d.items(),key=lambdax:x[1],reverse=True): ifV>=cnt: cnt=V print(K,'rate: ',V/count) else: break; rate()
金易龙5087请问用python的pandas库如何实现计算某一个元素在另一个类别中出现的次数? -
沈世尤18895924197 ______ 如果用pivot_table,需要给df重复出一列data_type df['col']=df.data_type df.pivot_table(index='year',columns='col',values='data_type',aggfunc=pd.Series.value_counts) col 1 2 3 year 2006 4 4 42007 3 3 22008 3 3 4 用交叉表其实最方便:pd.crosstab(df.year,df.data_type) data_type 1 2 3 year 2006 4 4 42007 3 3 22008 3 3 4
金易龙5087用python写一个程序,统计文件中url的出现次数,急求
沈世尤18895924197 ______ <p>由于时间和技术的原因,我暂时只能写出这样的来</p> <p>windowsxp+gvim+python2.7 </p> import os from collections import OrderedDict a=os.listdir("D:/test/python") #需要统计的文件夹 dicttt={} aa=len(a) i=0 for i in range(0,aa): ffname=...
金易龙5087Python 矩阵 连续出现 1 的次数 -
沈世尤18895924197 ______ #coding:utf-8 def checknum(l,n=1): #计算列表中连续=n的数目,返回最大连续数 res=[] count=0 for i in l: if i == n: count+=1 else: res.append(count) count=0 return max(res) d=[ [1, 0, 0,1], [1, 1, 1,1], [1, 1, 0,0], [1, 1, 1,1], [0, 0, 0,1] ] d2=[[i[j] for i in d] ...
金易龙5087求助python的for循环 -
沈世尤18895924197 ______ 看题看错,我再想 ========== 做出,运行环境python 3.2,>3.0可运行 import functools def occurrences(text1, text2): #一行流代码,利用字典统计text2中所含text1的数量 s_items=dict(map(lambda i:(i[0],text2.count(i[0])),dict( zip(text1,[0]*len(text1)...
金易龙5087编写一个程序,从键盘先输入n的值,然后输入n个正整数,输出每个数出现的次数 -
沈世尤18895924197 ______ #include <iostream> using namespace std; void main () { int i,n,x[100]; cout<<"输入n:"; cin>>n; for(i=0;i<n;i++) { cout<<"输入第"<<i+1<<"个整数:"; cin>>x[i]; } cout<<"平方:"<<endl; for(i=0;i<n;i++) cout<<x[i]*x[i]<<" "; cout<<endl; }
金易龙5087python 查找一个元素在list里出现了多少次 -
沈世尤18895924197 ______ ##注意:最左边每个=表示一个空格 def cnt(s1,s2):====n,len1,len2=0,len(s1),len(s2)====for i in range(len1-len2+1):========if s1.startswith(s2,i):============n+=1====return n print(cnt('aaaa','aa')) print(cnt('bcabcabca','abc')) print(cnt('ab','ab'))