java@override

【CSDN 编者按】240 行纯 Java 编写 Java 分析器是完全可行的,生成的分析器甚至可用于分析性能问题。它并不是为了取代 async-profiler 之类的分析器而设计的,而是揭开分析器内部工作原理的神秘面纱。
原文链接:https://mostlynerdless.de/blog/2023/03/27/writing-a-profiler-in-240-lines-of-pure-java/
未经授权,禁止转载!
作者 | Johannes Bechberger 译者 | 弯月责编 | 王子彧 出品 | CSDN(ID:CSDNnews)几个月前,我开始着手编写分析器。如今,这些代码已经变成了我的分析器验证工具的基础。这个项目的唯一问题是:我想从零开始编写一款非安全点偏差分析器。这其中涉及大量 C/C++/Unix 编程,但不是每个人都能阅读 C/C++ 代码。
什么是安全点偏差?
安全点是 JVM 具有已知的、确定的状态,并且所有线程都已停止的时间点。JVM 本身需要安全点来执行主要的垃圾收集、类定义、方法去优化等。线程会定期检查它们是否应该进入安全点,例如,在方法入口、出口或循环回跳处进行检查。仅在安全点进行分析的分析器具有固有的偏差,因为它包含的帧都来自线程进行安全点检查时调用的方法所在的位置。唯一的优点是,在安全点遍历堆栈不太容易出错,因为堆和栈的变动都很少。
相关的更多信息,请参见 Seetha Wenner 撰写的文章《 Java 安全点与异步分析》(参考链接:https://seethawenner.medium.com/java-safepoint-and-async-profiling-cdce0818cd29),以及 Nitsan Wakart 的经典文章《Safepoints: Meaning, Side Effects and Overheads》(参考链接:http://psy-lob-saw.blogspot.com/2015/12/safepoints.html)。
总而言之,安全点偏差分析器无法提供应用程序的整体视图,但仍然有助于从更高的角度分析主要的性能问题。
本文旨在用每个人都能理解的纯 Java 代码开发一个微型 Java 分析器。编写分析器不是造火箭,如果不考虑安全点偏差,我们可以编写一款实用的分析器,而且只需 240 行代码即可输出火焰图。该项目的源代码,请参见 GitHub(https://github.com/parttimenerd/tiny-profiler)。
我们在 Java 代理启动的守护线程中实现分析器。这样,可以方便我们同时运行分析器与需要分析的 Java 程序。分析器的主要构成如下:
Main:Java 代理的入口点,分析线程的启动器。
Options:解析并存储代理选项。
Profiler:容纳了分析循环。
Store:存储并输出采集到的结果。
Main类首先,从代理入口点的实现着手:
public class Main { public static void agentmain(String agentArgs) { premain(agentArgs); } public static void premain(String agentArgs) { Main main = new Main(); main.run(new Options(agentArgs)); } private void run(Options options) { Thread t = new Thread(new Profiler(options)); t.setDaemon(true); t.setName("Profiler"); t.start(); }}当代理附加到 JVM 时调用 premain。因为用户将 -javagent 传递给了 JVM。对于我们的示例来说,这意味着用户运行 Java 时使用了如下命令:
java -javaagent:./target/tiny_profiler.jar=agentArgs …但也有可能是用户在运行时附加了代理。在这种情况下,JVM 将调用方法 agentmain。如果想了解有关 Java 代理的更多信息,请参见 JDK 文档(https://docs.oracle.com/en/java/javase/17/docs/api/java.instrument/java/lang/instrument/package-summary.html)。
请注意,我们必须在生成的 JAR 文件的 MANIFEST 文件中设置 Premain-Class 和 Agent-Class 属性。
Java 代理解析代理参数,获取选项,再由 Options 类建模并解析这些选项:
public class Options { /** interval option */ private Duration interval = Duration.ofMillis(10); /** flamegraph option */ private Optional flamePath; /** table option */ private boolean printMethodTable = true; ...}Main 类的核心是 run 方法:Profiler 类实现了 Runnable 接口,因此我们可以直接创建线程:
Thread t = new Thread(new Profiler(options));接着,将这个分析器线程标记为守护线程,这意味着即使在分析器线程运行期间,JVM 也会在被分析的应用程序结束时终止:
t.setDaemon(true);下面,启动线程。但这需要先给线程命名,这一步非必需,但可方便调试。
t.setName("Profiler");t.start();Profiler类实际的采样在 Profiler 类中处理:
public class Profiler implements Runnable { private final Options options; private final Store store; public Profiler(Options options) { this.options = options; this.store = new Store(options.getFlamePath()); Runtime.getRuntime().addShutdownHook(new Thread(this::onEnd)); } private static void sleep(Duration duration) { // ... } @Override public void run() { while (true) { Duration start = Duration.ofNanos(System.nanoTime()); sample(); Duration duration = Duration.ofNanos(System.nanoTime()) .minus(start); Duration sleep = options.getInterval().minus(duration); sleep(sleep); } } private void sample() { Thread.getAllStackTraces().forEach( (thread, stackTraceElements) -> { if (!thread.isDaemon()) { // exclude daemon threads store.addSample(stackTraceElements); } }); } private void onEnd() { if (options.printMethodTable()) { store.printMethodTable(); } store.storeFlameGraphIfNeeded(); }我们来看看这个构造器,最有意思的是下面这行代码:
Runtime.getRuntime().addShutdownHook(new Thread(this::onEnd));这行代码的意思是,让 JVM 在关闭时调用 Profiler::onEnd。这很关键,因为分析器线程已被默默中止,而我们仍想输出捕获的结果。
有关关闭挂钩的更多信息,请参见 Java 文档。(https://docs.oracle.com/en/java/javase/17/docs/api/java.base/java/lang/Runtime.html#addShutdownHook(java.lang.Thread))。
接下来,再看看 run 方法中的分析循环:
while (true) { Duration start = Duration.ofNanos(System.nanoTime()); sample(); Duration duration = Duration.ofNanos(System.nanoTime()) .minus(start); Duration sleep = options.getInterval().minus(duration); sleep(sleep);}此处调用了 sample 方法,并在这之后休眠了一段时间,为的是确保按照 interval(通常为 10 毫秒)的节奏调用 sample 方法。
这个 sample 方法中包含核心的采样处理:
Thread.getAllStackTraces().forEach( (thread, stackTraceElements) -> { if (!thread.isDaemon()) { // exclude daemon threads store.addSample(stackTraceElements); }});此处,我们使用 Thread::getAllStackTraces 方法来获取所有线程的堆栈跟踪。这会触发一个安全点,这也是这款分析器存在安全点偏差的原因。获取线程子集的堆栈跟踪是没有意义的,因为 JDK 中没有使用这些信息的方法。在线程的子集上调用 Thread::getStackTrace 会触发许多安全点,不仅仅是一个,因此导致的性能损失甚至会超过获取所有线程的跟踪。
Thread::getAllStackTraces 的结果经过了过滤,因此不包含守护线程(比如Profiler 线程或未使用的 Fork-Join-Pool 线程)。我们将正确的跟踪传递给 Store,由它来执行之后的后期处理。
Store类这是这款分析器的最后一个类,也是迄今为止最重要的后期处理、存储和输出所收集信息的类:
package me.bechberger;import java.io.BufferedOutputStream;import java.io.OutputStream;import java.io.PrintStream;import java.nio.file.Path;import java.util.HashMap;import java.util.List;import java.util.Map;import java.util.Optional;import java.util.stream.Stream;/** * store of the traces */public class Store { /** too large and browsers can't display it anymore */ private final int MAX_FLAMEGRAPH_DEPTH = 100; private static class Node { // ... } private final Optional flamePath; private final Map methodOnTopSampleCount = new HashMap<>(); private final Map methodSampleCount = new HashMap<>(); private long totalSampleCount = 0; /** * trace tree node, only populated if flamePath is present */ private final Node rootNode = new Node("root"); public Store(Optional flamePath) { this.flamePath = flamePath; } private String flattenStackTraceElement( StackTraceElement stackTraceElement) { // call intern to safe some memory return (stackTraceElement.getClassName() + "." + stackTraceElement.getMethodName()).intern(); } private void updateMethodTables(String method, boolean onTop) { methodSampleCount.put(method, methodSampleCount.getOrDefault(method, 0L) + 1); if (onTop) { methodOnTopSampleCount.put(method, methodOnTopSampleCount.getOrDefault(method, 0L) + 1); } } private void updateMethodTables(List trace) { for (int i = 0; i < trace.size(); i++) { String method = trace.get(i); updateMethodTables(method, i == 0); } } public void addSample(StackTraceElement[] stackTraceElements) { List trace = Stream.of(stackTraceElements) .map(this::flattenStackTraceElement) .toList(); updateMethodTables(trace); if (flamePath.isPresent()) { rootNode.addTrace(trace); } totalSampleCount++; } // the only reason this requires Java 17 :P private record MethodTableEntry( String method, long sampleCount, long onTopSampleCount) { } private void printMethodTable(PrintStream s, List sortedEntries) { // ... } public void printMethodTable() { // sort methods by sample count // the print a table // ... } public void storeFlameGraphIfNeeded() { // ... }}Profiler 调用 addSample 方法,该方法会展开堆栈跟踪元素,并将它们存储在跟踪树中(用于火焰图),并统计跟踪的所有方法的数量。
有意思的部分是 Node 类建模的跟踪树。基本思想是,当 JVM 返回时,每个跟踪 A -> B -> C(A 调用 B,B 调用 C,[C,B,A])都可以表示为根节点,其包含子节点 A、B和C,因此每个捕获的踪迹都是从根节点到叶节点的路径。我们可以数一数节点出现在跟踪中的次数。然后,使用它来输出 d3-flame-graph 的树数据结构,然后再用这个数据结构创建漂亮的火焰图,如下所示:
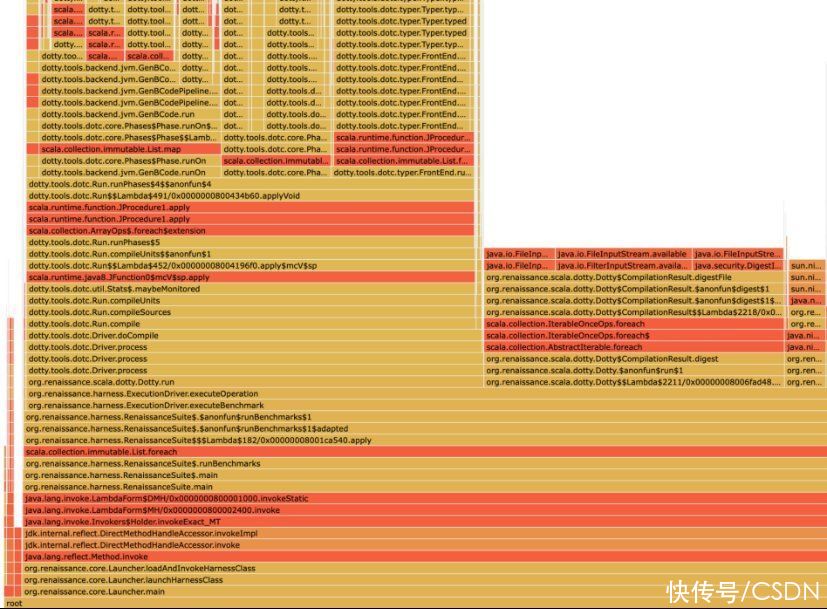
图:分析器根据renaissance dotty基准生成的火焰图
请记住,实际的 Node 类如下:
private static class Node { private final String method; private final Map children = new HashMap<>(); private long samples = 0; public Node(String method) { this.method = method; } private Node getChild(String method) { return children.computeIfAbsent(method, Node::new); } private void addTrace(List trace, int end) { samples++; if (end > 0) { getChild(trace.get(end)).addTrace(trace, end - 1); } } public void addTrace(List trace) { addTrace(trace, trace.size() - 1); } /** * Write in d3-flamegraph format */ private void writeAsJson(PrintStream s, int maxDepth) { s.printf("{ \\"name\\": \\"%s\\", \\"value\\": %d, \\"children\\": [", method, samples); if (maxDepth > 1) { for (Node child : children.values()) { child.writeAsJson(s, maxDepth - 1); s.print(","); } } s.print("]}"); } public void writeAsHTML(PrintStream s, int maxDepth) { s.print(""" " type="text/css" href="https: """); }Tiny-Profiler我将最终的分析器命名为 tiny-profiler,源代码在 GitHub 上( MIT 许可)。这个分析器应该可以在任何带有 JDK 17 或更新版本的平台上工作。用法相当简单:
# build itmvn package# run your program and print the table of methods sorted by their sample count# and the flame graph, taking a sample every 10msjava -javaagent:target/tiny-profiler.jar=flamegraph=flame.html ...你可以在renaissance dotty基准测试上运行,并创建如前所示的火焰图:# download a benchmark> test -e renaissance.jar || wget https://github.com/renaissance-benchmarks/renaissance/releases/download/v0.14.2/renaissance-gpl-0.14.2.jar -O renaissance.jar> java -javaagent:./target/tiny_profiler.jar=flamegraph=flame.html -jar renaissance.jar dotty...===== method table ======Total samples: 11217Method Samples Percentage On top Percentagedotty.tools.dotc.typer.Typer.typed 59499 530.44 2 0.02dotty.tools.dotc.typer.Typer.typedUnadapted 31050 276.81 7 0.06scala.runtime.function.JProcedure1.apply 24283 216.48 13 0.12dotty.tools.dotc.Driver.process 19012 169.49 0 0.00dotty.tools.dotc.typer.Typer.typedUnnamed$1 18774 167.37 7 0.06dotty.tools.dotc.typer.Typer.typedExpr 18072 161.11 0 0.00scala.collection.immutable.List.foreach 16271 145.06 3 0.03...此示例的开销在我的 MacBook Pro 13″ 上大约为 2%,间隔为 10 毫秒,如果不考虑安全点偏差,结果是可接受的。
总结
综上所述,用 240 行纯 Java 编写 Java 分析器完全可行,生成的分析器甚至可用于分析性能问题。这个分析器并不是为了取代 async-profiler 之类的分析器而设计的,我的目标是揭开分析器内部工作原理的神秘面纱。

郜融乖2911JAVA方法中的“return this”是什么含义? -
简秀衫13597001523 ______ 连续操作类里方法,每次返回类实例,用return this; class Test2 { String s=""; public static void main(String[] args) { Test2 t = new Test2(); t.method("111"); t.method("222"); t.method("333"); t.method2(); } public Test2 method(String ...
郜融乖2911如何用JAVA将数据库中的数据导入到excel表格 -
简秀衫13597001523 ______ 第一步:如何用POI操作Excel @Test public void createXls() throws Exception{ //声明一个工作薄 HSSFWorkbook wb = new HSSFWorkbook(); //声明表 HSSFSheet sheet = wb.createSheet("第一个表"); //声明行 HSSFRow row = sheet.createRow(7); //声明列 HSSFCell cel = row.createCell(3); //写入数据 cel.setCellValue("你也好");
郜融乖2911Java - java产生StackOverflowError的原因是什么 -
简秀衫13597001523 ______ Java-java产生StackOverflowError的原因是内存耗尽了,一般是由于程序中有递归或者死循环导致,检查一下程序就好了.
郜融乖2911java中为什么要用方法重载 -
简秀衫13597001523 ______ 重载的意义在于扩展父类的功能,如果有两个类A和B,继承C,那么在C的方法只需要定义A和B相同的功能,而在各个子类中扩展子类具体的实现.这是面向对象的设计
郜融乖2911JAVA中Thread类的start()方法引用 -
简秀衫13597001523 ______ System.exit(1); 因为这里,你在主线程里把你的线程停掉了.......System.exit(0)是正常退出程序,而System.exit(1)或者说非0表示非正常退出程序
郜融乖2911java中的mouse事件 -
简秀衫13597001523 ______ mouseover 鼠标移到某个对象上发生的事件 mouseout 鼠标从某个对象上离开发生的事件 click 鼠标单击事件 dclick 鼠标双击事件 clickdown 鼠标按下不松开发生的事件 clickdown 鼠标松开鼠标按键发生的事件
郜融乖2911Java的龟兔赛跑多线程问题 -
简秀衫13597001523 ______ public class Competition { private volatile static boolean gameOver = false;//用来标记是否有人到达终点,到达终点后游戏结束 //乌龟的实现方式 static class Tortoise implements Runnable{ private volatile int total = 0;//用来记录当前已经前行了...
郜融乖2911java中实现多态的机制是什么?
简秀衫13597001523 ______ 方法的重写Overriding和重载Overloading是Java多态性的不同表现.重写Overriding是父类与子类之间多态性的一种表现,重载Overloading是一个类中多态性的一种表现.
郜融乖2911用JAVA编程从键盘输入一个数,判断该数是否是完全数怎么做 -
简秀衫13597001523 ______ 代码如下,希望能帮到你~! import java.util.Scanner; public class PerfectNumber { /** * @param args */ public static void main(String[] args) throws Exception { // TODO Auto-generated method stub Scanner in = new Scanner(System.in); ...