hadoop1.0组件
K.K在《未来十二大趋势》中认为,我们正处于一个数据流动的时代。商业乃数据之商业。归根结底,你在处理的都是数据。
的确,当数据成为新的核心生产要素之际,数据分析就犹如最重要的生产工具之一,决定着企业在数字化时代生产力水平。近年来,无论国外的Snowflake、Databricks,还是国内StarRocks、PingCAP,大批数据分析型公司涌现,都旨在满足越来越多的数据分析需求,帮助各种企业充分释放数据生产力。
这其中,StarRocks就是数据分析领域一颗冉冉升起的新星。在短短几年时间里,StarRocks在Github获得star 6300+,成为同类开源数据库项目里增长最快的,并且在2022年底正式捐赠给 Linux Foundation,吸引到全球开发者和用户参与未来社区的建设。
正如StarRocks TSC Member、镜舟科技 CTO 张友东所言,StarRocks希望通过技术创新来简化数据技术栈,通过一个引擎实现全场景的“One Data、All Analytics”愿景。

为何需要“One Data,All Analytics”
当前,人工智能、大数据、物联网等数字化技术在不断提升企业生产力的同时,随之而来就是复杂性的持续提升。这种复杂性在数据领域体现的尤为明显,尤其是数据技术与业务场景的不断融合,复杂性困扰着诸多身处数字化转型的企业。
复杂性首先体现在数据本身,数据正加速走向海量化和多样化。过去,一家企业往往以结构化数据为主,数据规模通常是TB级别;现在,文本数据、轨迹数据、日志数据等非结构化数据大幅增加,PB级数据量正成为越来越多企业的常态。

其次,企业如今的业务场景日趋复杂,随之而来的就是数据栈相关技术、工具、产品大量增加。从过去单一的数据仓库,到现在指标平台、交互式分析、实时分析、流计算等等,企业面临的数据栈环境复杂程度远胜以往,并且随着AI相关技术融入,这种复杂性还在持续增加。
第三,数据消费需求的复杂性大幅提升。过去,数据消费仅仅是管理层少数人的“权力”;现在,“人人用数”已经成为众多企业追求的目标。例如,有些走在前沿的互联网、金融等企业,甚至一名普通业务员工都是数据消费者,并且在日常业务中随时会进行数据分析。
因此,在海量数据环境成为既定事实的情况下,企业在数据领域所面临的复杂性挑战将是数字化转型中一道必须面临的难题。在张友东看来,“One Data,All Analytics”是化解数据分析复杂性的关键,而StarRocks3.0版本的推出,为实现“One Data,All Analytics”目标前进了一大步。
StarRocks 3.0,产品大进阶
众所周知,数据分析类产品拥有多年历史。在大数据兴起之前,Teradata、Greenplum等传统数据仓库一直占据着主流市场位置;随着大数据兴起,以Hadoop 为代表的大数据平台迅速成为数据分析的基础平台;如今,云原生、湖仓一体等技术的兴起,加速推动着数据分析产品的创新。
当前,数据分析类相关的公司众多。不过,StarRocks用出色表现吸引了业界的大量关注。自从2021年9月份正式开源以来,StarRocks已成长为开源领域的明星项目,获得了全球开发者的认可。在笔者看来,StarRocks之所以在短时间即获得阶段性的成功,关键在于产品的迭代速度和创新能力。
从开源至今,StarRocks已经历了三个大版本的迭代,从1.0版本主打性能,到2.0版本围绕融合统一,再到现在3.0版本围绕湖仓一体的创新,StarRocks成为当下数据分析领域现象级的产品。
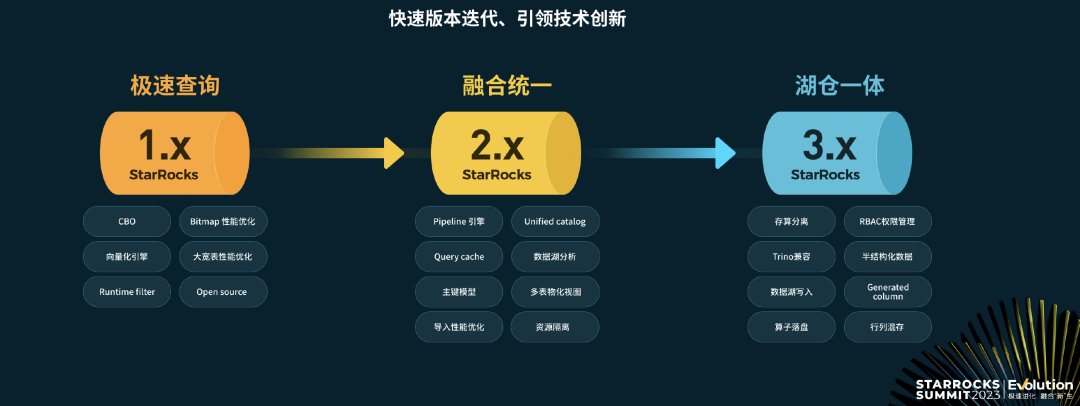
以数据仓库架构为例,存算分离是大势所趋。随着云原生等技术的高速发展,通过存算分离架构,计算、存储等资源可以更好地弹性化,以应对业务对于资源的使用,从而实现成本、效率的最优化。StarRocks 3.0同样采用了存算分离架构,架构设计高度抽象且极简,无需依赖复杂组件,具有极强的扩展性和弹性;并且支持Multi-Warehouse,多个Warehouse共享一份数据,不同 Warehouse 应用在不同工作负载,计算资源可以进行物理隔离,内部按需独立弹性伸缩。
“存算分离架构真正带来两大价值:降本增效和弹性伸缩。像在存储层面,采用存算分离架构后的StarRocks 3.0整体存储成本可以下降80%,而计算节点则因为无状态,可以通过快速弹性、跨可用区部署等方式来提高计算的可用性,并且计算资源能够进行物理隔离,按需独立弹性伸缩。”张友东介绍道。
另外,湖仓走向一体化也是数据分析产品的一大重要趋势。通常,企业在经历了多年的数字化转型之后,都会存在着数据仓库和数据湖两种数据分析技术栈,它们各具特点与优势,数据仓库往往具备数据质量高、性能出色、实时分析强等优势,而数据湖则可以存储各种不同类型的数据,扩展性和开放性强。因此,融合数据仓库与数据湖的各自优势就成为业界努力的方向。
当前,业界并不缺少湖仓相关的解决方案。比如在湖上性能不满足,采用湖上建仓的方案加速查询;再如数据仓库扩展查询外部数据湖能力等。
张友东直言,这些方案更像是一种组合式方案,并没有真正做到湖仓一体,“湖仓一体意味着一套架构满足所有数据分析的需求,也即One Data,All Analytics。”
以StarRocks 3.0的湖仓一体化架构为例,实现了数据统一存储管理,一份数据作为 Single source of truth;另外,强大的分析引擎可以基于一份数据,满足包括BI 报表、交互式分析、实时分析、ETL 数据加工等场景的查询诉求;更加关键的是,具备按需数据加工/查询加速的能力。

“未来数据分析演进的趋势肯定是湖仓一体,用户无需关注建湖还是建仓,核心目标是低成本、高效的解决数据分析问题。”张友东补充道。
此外,随着数据量和业务复杂性的大幅提升,使得ETL成为一件极为辛苦的工作,通常需要耗费大量人力、精力在ETL相关工作上。对此,StarRocks 3.0也在瞄准No ETL的方向,在整个数据管理中减少ETL的工作量,并且通过物化视图让用户尽量不感知ETL,从全链路层面致力于简化ETL的pipeline。
毫无疑问,StarRocks 3.0版本的推出是StarRocks项目发展的一个关键节点。这意味着StarRocks 产品力已经实现重要的突破,可以助力用户实现全场景的数据分析架构统一,也为自身带来了更加广阔的市场空间。
多个头部客户青睐,StarRocks未来值得期待
随着数据驱动型应用大量涌现,数据分析、数据消费需求也随之产生。Gartner认为,数据分析已成为企业数字化转型中致力于建设的核心能力。因此,数据分析赛道未来具有极为光明的前景。
毫无疑问,从StarRocks的社区发展、用户群、商业生态建设等情况拉看,StarRocks正处于一个高速发展的极端,未来值得更多的期待。
其一,得益于对于开源理念的坚持,StarRocks 开源社区一直处于非常活跃的状态,为后续的发展带来了十足的生命力。目前,社区开发工作由镜舟科技主导推进,并且贡献了70%以上的核心代码;此外,阿里云、腾讯、火山引擎、滴滴出行等头部企业已经积极参与到社区之中,并且持续给社区贡献了物化视图、CN 弹性节点等诸多重要特性。

其二,得益于行业头部客户的积极参与和产品创新力的提升,StarRocks产品在金融、零售、物流、制造和互联网等多个行业头部用户的复杂业务场景中得到锤炼。据悉,目前有超过 300家市值10亿美金以上的大型用户在生产环境使用 StarRocks,场景覆盖 BI 报表、交互式探寻分析、实时分析、湖仓分析等一系列场景,未来有望在场景应用中持续推动产品创新与快速迭代。
其三,StarRocks 重视商业生态的建设。除了头部行业用户使用之外,StarRocks目前与国内各大云服务商均有合作,致力于借助云计算这个大生态来推动开源项目的商业化,让产品走向更加广泛的市场群体,在市场竞争中获得成长。
“相比于北美等发达市场,中国市场的数据分析还有巨大的潜力空间,StarRocks希望通过技术创新帮助更多用户实现One Data,All Analytics。”张友东最后表示道。
","gnid":"9ebacc99d91737529","img_data":[{"flag":2,"img":[{"desc":"","height":"720","title":"","url":"https://p0.ssl.img.360kuai.com/t01572a30185f4fe8ae.jpg","width":"1080"},{"desc":"","height":"873","title":"","url":"https://p0.ssl.img.360kuai.com/t0198537005c7b47e89.jpg","width":"1080"},{"desc":"","height":"406","title":"","url":"https://p0.ssl.img.360kuai.com/t01429a899500eab03f.jpg","width":"1080"},{"desc":"","height":"484","title":"","url":"https://p0.ssl.img.360kuai.com/t01e04efa626a35066c.jpg","width":"1080"},{"desc":"","height":"720","title":"","url":"https://p0.ssl.img.360kuai.com/t01ff5df2bed1746eee.jpg","width":"1080"}]}],"original":0,"pat":"art_src_3,fts0,sts0","powerby":"pika","pub_time":1701676260000,"pure":"","rawurl":"http://zm.news.so.com/f5ca5bb3301a9c7b41f42ab68dcaf553","redirect":0,"rptid":"ab73968d7376756f","rss_ext":[],"s":"t","src":"大数据在线","tag":[{"clk":"ktechnology_1:大数据","k":"大数据","u":""}],"title":"StarRocks上新,“One Data、All Analytics”还有多远?
房兔该2077Hadoop集群以外的机器如何访问Hadoop集群,进行提交文件,下载文件? -
舒舒葛13192493773 ______ 集群以外的机器如何访问Hadoop集群,并像集群中提交作业和传送数据 (1)首先,在机器上安装nutch或者hadoop (2)配置两个文件 hadoop-site.xml: fs.default.name hdfs://gc04vm12:9000 mapred.job.tracker gc04vm12:9001 (3)这样便能执行命...
房兔该2077如何在Ubuntu下搭建Spark集群 -
舒舒葛13192493773 ______ 这里是结合Hadoop2.0使用的 1,download :http://spark.incubator.apache.org/downloads.html选择prebuilt:中hadoop2的下载,hadoop安装就不介绍了,spark节点可以不是hadoop节点,可以是一个hadoop客户端. 2,download scala,http://www....
房兔该2077yarn是一种新的hadoop资源管理器,以下哪些开源组件可以运行在hadoop yarn上 -
舒舒葛13192493773 ______ 1. MapReduce On YARN:YARN天生支持,目前已非常完善(从YARN将要发布2.1.0-beta版可看出,较之前版本,这一块基本没有修改).2. Tez On YARN:一个DAG计算框架,直接修改自MapReduce,继承了MapReduce的扩展性好和容错性好等优点3. Storm On YARN:实时计算框架Storm运行在YARN上,,项目状态:开发进行中,已发布一个版本.
房兔该2077如何部署Apache Hadoop 2.2.0 Eclipse插件 -
舒舒葛13192493773 ______ 1.下载 下载winghc/hadoop2x-eclipse-plugin 压缩包. 2.提取 提取到本地路径(如“C:\hadoop2x-eclipse-plugin”). 3.搭建 在命令行窗口中打开'\src\contrib\eclipse-plugin' C:\>cd C:\hadoop2x-eclipse-plugin\src\contrib\eclipse-plugin 运行...
房兔该2077对象存储服务是一种分布式为用户提供海量数据存储的服务... - 上学吧
舒舒葛13192493773 ______ 1、hadoop是java语言开发,运行时候需要用jdk的jre环境,故必须配置. 2、对于一个需要jdk环境支持的项目来说,有两种获取方:直接获取系统的JAVA_HOME或是项目的配置文件中的配置的JAVA_HOME.显然hadoop是走的第二种方式,故在运行hadoop时,你不配置系统的JAVA_HOME也是可以接受的,只是一般都会配置. 再思考下吧.
房兔该2077hadoop分布式每次都要重新启动吗 -
舒舒葛13192493773 ______ hadoop分布式每次都要重新启动1 配置hosts文件,将主机名和对应IP地址映射.如图中Master、Slave1和Slave2是我们要搭建分布式环境的机器.Master为主机,Slavex为从机.2 配置SSH的无密码登录:可新建专用用户hadoop进行操作,cd...
房兔该2077为什么会有mapreduce和spark
舒舒葛13192493773 ______ MapReduce从出现以来,已经成为Apache Hadoop计算范式的扛鼎之作.它对于符合其设计的各项工作堪称完美:大规模日志处理,ETL批处理操作等. 随着Hadoop使用范围的不断扩大,人们已经清楚知道MapReduce不是所有计算的最佳框...
房兔该2077如何使用spark将程序提交任务到yarn - Spark - about云开发 -
舒舒葛13192493773 ______ 使用脚本提交 1.使用spark脚本提交到yarn,首先需要将spark所在的主机和hadoop集群之间hosts相互配置(也就是把spark主机的ip和主机名配置到hadoop所有节点的/etc/hosts里面,再把集群所有节点的ip和主机名配置到spark所在主机的/etc/...