用训练的出的模型进行预测

【编者按】在线编程平台 Replit 分享了一篇如何使用 Databricks、Hugging Face 和 MosaicML 训练大型语言模型(LLMs)的文章,分享了他们在训练自家编程大模型(LLM)的过程、经验和教训,他们把整个过程分为三个阶段,数据管道、模型训练和推理。CSDN借助 ChatGPT 和 Claude 联合翻译,以飨读者!
原文地址:https://blog.replit.com/llm-training
责编 | 王子彧
大型语言模型(如 OpenAI 的 GPT-4 或 Google 的 PaLM )已经席卷了人工智能领域。然而,大多数公司目前都没有能力训练这些模型,并且完全依赖于只有少数大型科技公司提供的技术。
在 Replit,我们投入了大量的基础设施来从头开始训练自己的大型语言模型。在本文中,我们将概述如何训练 LLMs,从原始数据到在用户面向生产环境中的部署。我们将讨论我们在此过程中面临的工程挑战,以及我们如何利用我们认为构成现代 LLM 堆栈的供应商:Databricks、Hugging Face 和 MosaicML。
虽然我们的模型主要是用于代码生成的用例,但所讨论的技术和经验教训适用于所有类型的 LLMs,包括通用语言模型。在未来的几周和几个月中,我们计划深入探讨我们的流程的细节。
为什么要训练自己的 LLMs?Replit 的 AI 团队最常见的问题之一是“为什么要训练自己的模型?”公司决定训练自己的 LLMs 的原因有很多,从数据隐私和安全到对更新和改进的更多控制。
在 Replit,我们主要关心的是定制化、减少依赖和成本效益。
个性化定制。训练自定义模型允许我们根据特定的需求和要求进行定制,包括平台特定的功能、术语和上下文,这些在通用模型如 GPT-4 或仅限代码的模型如 Codex 中都无法很好地覆盖。例如,我们的模型经过训练,可以更好地处理在 Replit 上流行的特定基于 Web 的语言,包括 Javascript React (JSX) 和 Typescript React (TSX)。
降低依赖性。虽然我们始终会根据需要使用适当的模型,但我们认为减少对少数人工智能供应商的依赖是有好处的。这不仅适用于 Replit,也适用于更广泛的开发者社区。这就是为什么我们计划开源一些我们的模型,这是在没有训练它们的手段的情况下无法实现的。
成本效益。虽然成本将继续下降,但 LLMs 对于全球开发者社区来说仍然成本过高。在 Replit,我们的使命是将下一个亿的软件创作者带上线。我们认为,印度手机上编写代码的学生应该能够访问与硅谷专业开发人员相同的人工智能。为了实现这一目标,我们训练定制的模型,这些模型更小、更高效,并可以以大大降低的成本进行托管。
数据管道、来源及处理数据管道LLM 模型需要大量的数据进行训练。为了训练它们,需要构建强大的数据管道,这些管道高度优化,同时又足够灵活,能够轻松包含新的公共和专有数据来源。
数据来源我们首先以“数据来源”作为我们的主要数据来源,该数据源可在 Hugging Face 上获得。Hugging Face 是一个极好的数据集和预训练模型资源。他们还提供了许多有用的工具,包括用于分词、模型推断和代码评估的工具,这些工具作为 Transformers 库的一部分提供。
“数据来源”是由 BigCode 项目提供的。有关数据集构建的详细信息可参考 Kocetkov et al. (2022)。在去重之后,版本 1.2 的数据集包含大约 2.7TB 的可许可证源代码,涵盖了超过 350 种编程语言。
Transformers 库在抽象出许多与模型训练相关的挑战方面做得非常好,包括处理大规模数据。但是,我们发现它对我们的过程来说不够充分,因为我们需要对数据进行额外的控制,并能够以分布式方式处理数据。
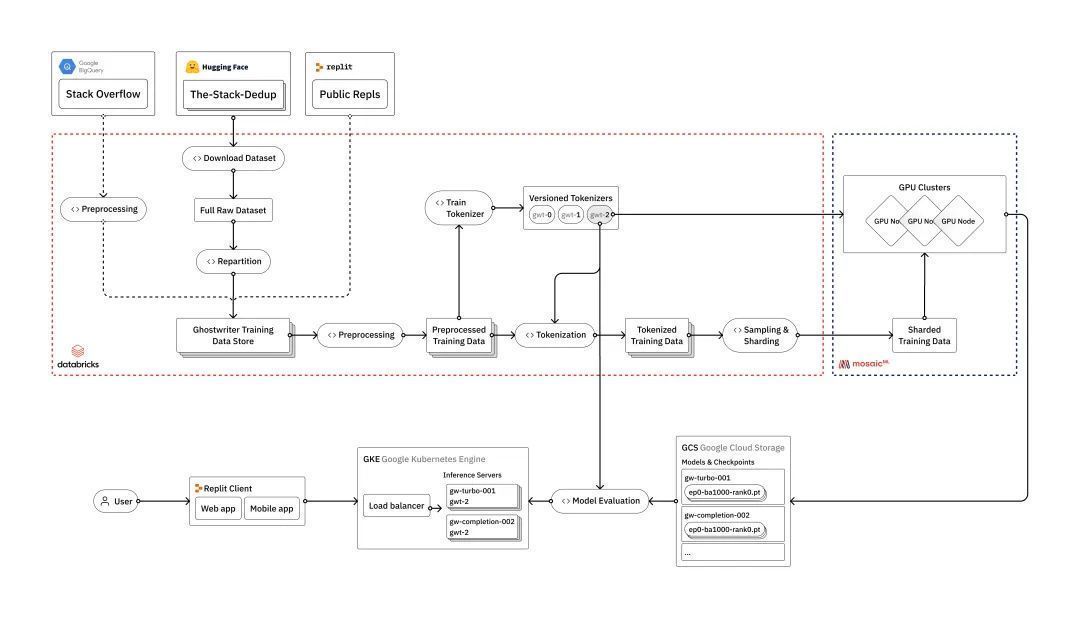
当需要进行更高级的数据处理时,我们使用 Databricks 来构建数据管道。这种方法还使我们能够轻松地将其他数据源(例如 Replit 或 Stack Overflow)引入我们的处理过程中,这是我们计划在未来的迭代中做的。
首先,我们需要从 Hugging Face 下载原始数据。我们使用 Apache Spark 将数据集构建过程并行化到每种编程语言中。然后,我们重新分区数据,并使用优化设置将其以 parquet 格式重新编写,以便进行下游处理。
接下来,我们转向数据清理和预处理。通常,重要的是对数据进行去重和修复各种编码问题,但是 The Stack 已经使用 Kocetkov 等人(2022)提出的一种近似去重技术为我们完成了这项工作。然而,一旦我们开始将 Replit 数据引入我们的管道中,就必须重新运行去重处理过程。这就是使用 Databricks 这样的工具的好处,我们可以将 The Stack、Stackoverflow 和 Replit 数据视为较大数据湖中的三个源,并根据需要在下游处理中利用它们。
使用 Databricks 的另一个好处是,我们可以对底层数据运行可扩展和可追踪的分析。我们对数据源运行各种摘要统计信息,检查长尾分布,并诊断过程中的任何问题或不一致性。所有这些都在 Databricks 笔记本中完成,还可以与 MLFlow 集成以跟踪和重现我们一路走来的所有分析。这一步,相当于定期对我们的数据进行一次 X 光检查,还有助于指导我们进行预处理的各种步骤。
对于预处理,我们采取以下步骤:
我们通过删除包括电子邮件、IP 地址和密钥在内的任何个人可识别信息(PII)来匿名化数据。
我们使用一些启发式方法来检测和删除自动生成的代码。
对于一些语言的子集,我们会删除不能编译或无法使用标准语法解析器进行解析的代码。
我们基于平均行长度、最大行长度和包含字母数字字符的百分比来过滤文件。
在进行分词 (tokenization) 之前,我们使用相同的数据集的随机子样本来训练自己的自定义词汇表 (vocabulary)。自定义词汇表可以使我们的模型更好地理解和生成代码内容,提高模型性能并加速模型训练和推断。
这一步是整个过程中最重要的步骤之一,因为它在我们的整个过程中的所有三个阶段(数据流水线、模型训练和推断)中都被使用到。这凸显了拥有一个强大而完整的基础架构对模型训练过程的重要性。
我们计划在以后的博客文章中深入探讨分词 (tokenization)。在高层次上,我们需要考虑的一些重要事项是词汇表大小、特殊标记 (special tokens) 以及保留用于 sentinel 标记 (sentinel tokens) 的空间。
一旦我们训练好了自定义词汇表,我们就对数据进行分词 (tokenize)。最后,我们构建我们的训练数据集,并将其写成分片格式,以便优化输入到模型训练过程中。
模型训练我们使用 MosaicML 训练我们的模型。在以前部署自己的训练集群之后,我们发现 MosaicML 平台为我们提供了几个关键的好处。
多个云提供商。Mosaic 允许我们利用不同云提供商的 GPU,而无需设置账户和所有必要的集成的开销。
LLM 训练配置。Composer 库有许多针对训练各种模型和不同类型的训练目标优化的配置。
托管基础架构。他们托管的基础架构为我们提供编排、效率优化和容错性(即从节点故障中恢复)。
在确定我们模型的参数时,我们考虑模型大小、上下文窗口、推理时间、内存占用量等方面的各种权衡。较大的模型通常提供更好的性能,并且更容易进行迁移学习。然而,这些模型在训练和推理方面都有更高的计算要求。后者对我们来说特别重要。Replit 是一个性能像本地应用程序的云原生 IDE,因此我们的代码补全模型需要非常快速。因此,我们通常倾向于选择内存占用量和低延迟推理的较小模型。
除了模型参数外,我们还可以选择各种各样的训练目标,每个目标都有其自己独特的优点和缺点。最常见的训练目标是下一个令牌预测。这通常对代码补全有效,但未考虑文档中下游的上下文。这可以通过使用“填补中间”目标来缓解,在该目标中,文档中的一系列令牌被遮挡,模型必须使用周围的上下文预测它们。另一种方法是 UL2 (无监督隐语言学习),它将不同的语言模型训练目标框架为去噪任务,模型必须恢复给定输入的丢失子序列。
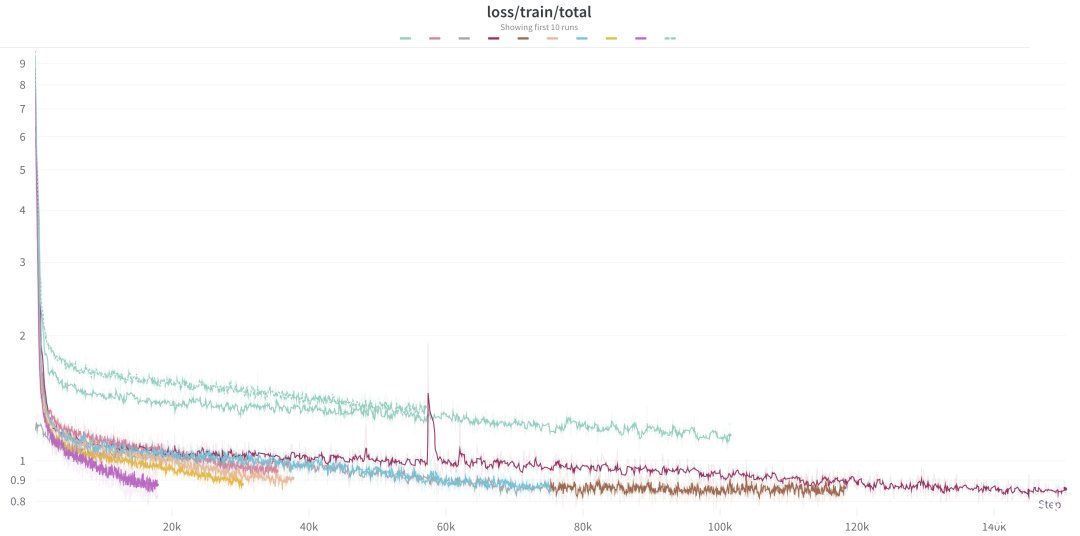
一旦我们决定模型配置和训练目标,我们就会在多节点 GPU 集群上启动训练运行。我们可以根据要训练的模型大小和训练过程的完成速度调整为每个运行分配的节点数。运行大型 GPU 集群非常昂贵,所以确保以最有效的方式利用它们非常重要。我们密切监控 GPU 利用率和内存,以确保我们的计算资源获得最大可能的利用。
我们使用 Weights & Biases 监控训练过程,包括资源利用率和训练进度。我们监控我们的损失曲线,以确保模型在训练过程的每一步中都在有效学习。我们还注意损失峰值。这些是损失值突然增加,通常表示训练数据或模型架构的潜在问题。因为这些情况通常需要进一步调查和潜在调整,我们在流程中执行数据确定性,以便更 easily 重现、诊断和解决任何这种损失峰值的潜在来源。
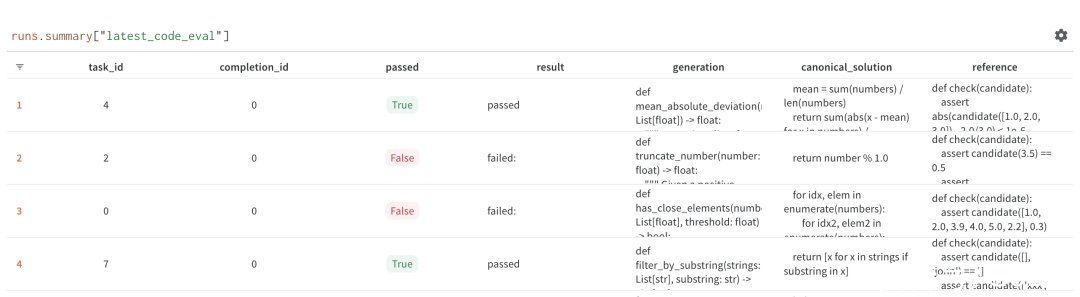
评估为了测试我们的模型,我们使用类似于 Chen 等人(2021)中描述的 HumanEval 框架的变体。我们使用模型根据给定的函数签名和文档字符串生成一个 Python 代码块。然后我们对产生的函数运行一个测试用例来确定生成的代码块是否按预期工作。我们运行多个样本并分析相应的 Pass@K 数字。
这种方法最适用于 Python,因为有现成的评估器和测试用例。但由于 Replit 支持许多编程语言,我们需要评估模型在更广泛的编程语言中的性能。我们发现这很难做到,并且没有广泛采用的工具或框架提供全面的解决方案。两个特定的挑战包括在任何编程语言中产生可重复的运行时环境,以及对于没有广泛使用的测试用例标准的编程语言存在歧义(例如,HTML、CSS 等)。幸运的是,“在任何编程语言中产生可重复的运行时环境”是我们在 Replit 的专长领域!我们正在构建一个评估框架,使任何研究人员都可以插入和测试他们的多语言基准测试。我们将在未来的博客文章中讨论这个问题。
一旦我们训练并评估了我们的模型,就该将其部署到生产环境中了。如前所述,我们的代码补全模型应该感觉很快,请求之间的延迟非常低。我们使用 NVIDIA 的 FasterTransformer和Triton Server加速我们的推理过程。FasterTransformer 是一个实现加速器引擎的库,用于变压器基神经网络的推理,Triton 是一个稳定快速的推理服务器,配置简单。这种组合为我们提供了一个高度优化的层,位于变压器模型和底层 GPU 硬件之间,可以进行大型模型的超快分布式推理。
部署我们的模型到生产环境后,我们能够使用 Kubernetes 基础架构根据需求自动扩展它。虽然我们在前面的博客文章中讨论了自动扩展,但值得一提的是,托管推理服务器会带来一套独特的挑战。这些包括大型工件(即模型权重)和特殊的硬件需求(即不同的 GPU 大小/数量)。我们的部署和集群配置已设计为能够快速可靠地发货。例如,我们的集群被设计为可以绕过个别区域中的 GPU 短缺,寻找最便宜的可用节点。
在将模型放在实际用户面前之前,我们喜欢先自己测试它,并对模型的“氛围”有所了解。我们之前计算的 HumanEval 测试结果虽然很有用,但是亲自使用模型没有什么能替代的,包括其延迟、建议的一致性和总体的有用性。将模型放在 Replit 工作人员面前就像翻转开关一样简单。一旦我们对它感到舒服,我们再翻转另一个开关,将其推出给我们的其他用户。
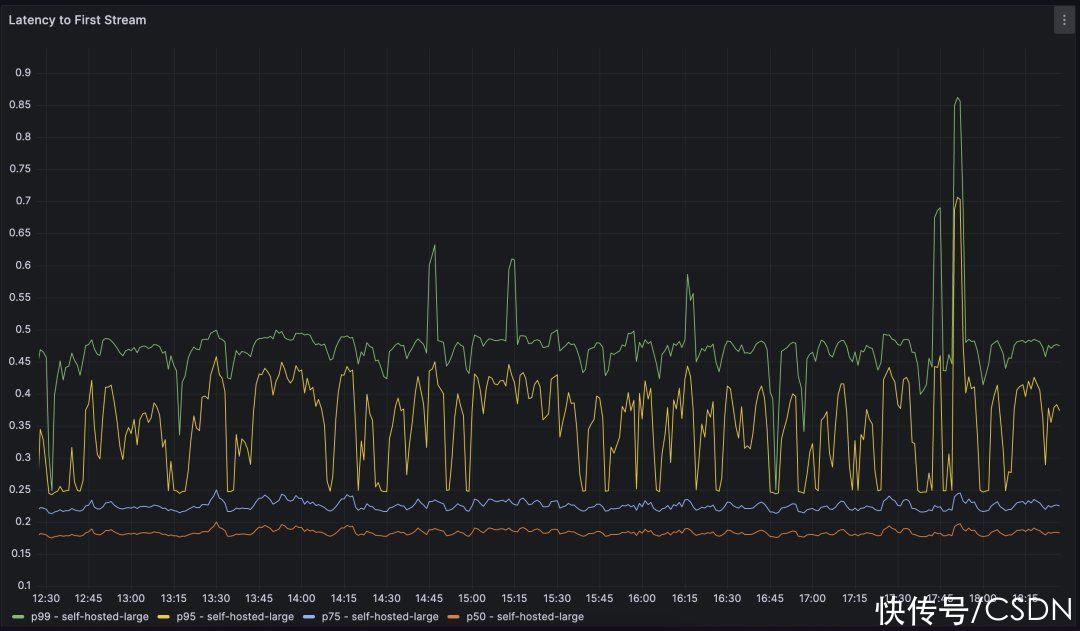
我们继续监控模型性能和使用指标。对于模型性能,我们监视诸如请求延迟和 GPU 利用率等指标。对于使用情况,我们跟踪代码建议的接受率,并根据多个维度进行细分,包括编程语言。这也使我们能够 A/B 测试不同的模型,并获得定量衡量一个模型与另一个模型的比较。
反馈和迭代我们的模型训练平台让我们能够在不到一天的时间内从原始数据训练出一个在生产环境中部署的模型。但更重要的是,它让我们能够训练和部署模型、收集反馈,并基于这些反馈快速迭代。
我们的流程也需要对底层数据源、模型训练目标或服务器架构的任何变化保持稳健。这使我们能够利用这个快速发展的领域中每天都会带来新的令人兴奋的进展和能力。
接下来,我们将扩展我们的平台,使我们能够利用 Replit 本身来改进我们的模型。这包括使用基于人类反馈的强化学习(RLHF)技术,以及使用从 Replit 赏金任务中收集的数据进行指令调整。
下一步虽然我们已经取得了巨大进步,但我们仍处于训练 LLM 的初期阶段。我们还有大量改进要做,许多困难问题还有待解决。随着语言模型的不断发展,这一趋势只会加速。与数据、算法和模型评估相关的一系列新的挑战将持续存在。
如果您对训练 LLM 的许多工程挑战感兴趣,我们很乐意与您交谈。我们欢迎反馈,并乐意听取您对我们遗漏的内容及您会如何不同的意见。

崔亲奚1327如何通俗的理解机器学习中的VC维,shatter和break point -
赵羽皆17676742278 ______ 来源:知乎 胡科学 通俗来讲,举个例子吧.假如你想训练出这样一个模型:根据人的身高和体重来预测这个人美还是丑.这是一个简单的二分类问题.现在想象你面前有一个平面直角坐标系.横轴(x轴)代表人的身高,纵轴(y轴)代表人的...
崔亲奚1327svmpredict怎么在matlab中使用 -
赵羽皆17676742278 ______ 先导入数据,之后训练模型svmtrain得到模型model,最后基于model用svmpredict进行预测 model = svmtrain(输出数据,输入数据,模型参数); predict_label = svmpredict(输出数据,输入数据, model);
崔亲奚1327怎么通过机器学习得到统计数据 -
赵羽皆17676742278 ______ 我的理解是这样的:1.人工智能:给机器赋予人类的智能,让机器能够像人类那样独立思考.当然,目前的人工智能没有发展到很高级的程度,这种智能与人类的大脑相比还是处于非常幼稚的阶段,但目前我们可以让计算机掌握一定的知识,更...
崔亲奚1327利用训练数据,用什么方法得到训练模型 -
赵羽皆17676742278 ______ 保存网络模型,然后把数据指向到神经网络就可以预测了.
崔亲奚1327无论{u}是否存在异方差性,用EViews练习加权最小二乘法估计模型,并用模型进行预测 -
赵羽皆17676742278 ______ ls y c x 进行普通最小二乘法回归,然后,在回归方程窗口,点estimation,点options,勾选加权最小二乘法,权数写1/abs(resid),确定即可.
崔亲奚1327机器学习训练过的模型能保存吗 -
赵羽皆17676742278 ______ 可以,记录训练出来的参数值即可,下次直接将输入带入训练好的模型中使用
崔亲奚1327如何用Python在10分钟内树立一个预测模型 -
赵羽皆17676742278 ______ 所谓预测模型我理解是机器学习的监督式算法. 常用的有 K 近邻, 决策树, 朴素贝叶斯等. 举例: 使用k近邻算法预测一个女的是不是美女: 我们抽取特征值:身高,体重,三围等. 你先设置一些经验数据,例如: A: 165CM 50KG, 23 32,31 美 B 150 60KG 23 23 23 丑 现在输入 C 163 45 25 30 30 选择K =3, 算法会找经验数据中和这个数据最接近的三个 值,判断这三个对象是 美 还是丑. 如果2,3个美,则预测为美.否则为丑. 对应的python代码在网上都有,估计20-30 行吧. 自己找找.
崔亲奚1327在spss建立ARIMA模型进行预测如何循环 -
赵羽皆17676742278 ______ 使用spss script,循环220次就可以了
崔亲奚1327运筹学的数学模型有哪些优缺点 -
赵羽皆17676742278 ______[答案] 优点:(1).通过模型可以为所要考虑的问题提供一个参考轮廓,指出不能直接看出的结果.(2).花节省时间和费用.(3).模型使人们可以根据过去和现在的信息进行预测,可用于教育训练,训练人们看到他们决策的结果,而不必作出实际的决策....